
본 포스팅은 성균관대학교 최재영 교수님의 '컴퓨터 비전(Computer Vision)' 강의 내용을 참고하여 작성되었습니다.
컴퓨터 비전 :: Feature Descriptors
Feature Description
· Good feature의 특징
(1) 반복성 : 같은 feature는 transformation해도 찾을 수 있다.
(2) 독특, 구분성(Saliency, 철극성)
(3) 간단, 효율(Compactness, efficiency) : 적은 수, 효율적
(4) 지역성(Locality) : 이미지에서 상대적 적은 위치를 차지 → robust to clutter and occlusion
· How to match?
- 템플릿 매칭은 변형(Scaling, Rotation)하면 사용할 수 없다.
→ Point descriptor를 사용
(1) Image patch : Pixel value를 이용하는 방법 → 밝기 변화에 영향을 받는다.
(2) Image gradients : Pixel difference를 이용하는 방법 → 밝기 차이를 보존하고 적은 메모리로도 관리 가능하지만, 템플릿 매칭과 마찬가지로 변형시 정보가 무용지물이 될 수 있다.
(3) Color histogram : 화소의 밝기정보를 histogram으로 만드는 방법 → Scaling과 Rotation에 Invariant하지만 다른 Image에서도 동일한 histogram을 얻을 수 있는 약점이 있다.

SIFT(Scale Invariant Feature Transform)
· SIFT Features corner
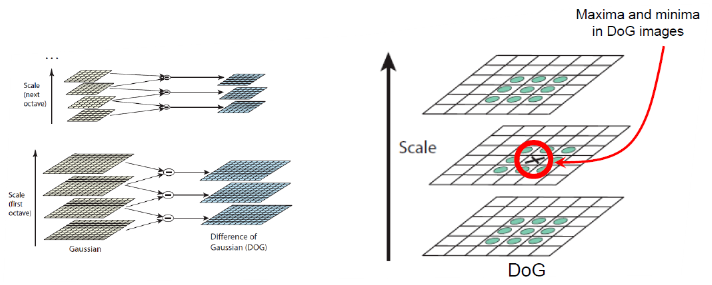
(1) Scale에 불변한 내용을 찾는 것 - DoG(approx. LoG)를 다양한 스케일로 적용
: NMS, find local keypoint candidates(minimum, maxima)
(2) Quadratic function에서 maximum fit → Localizable corner
: 아래 그림과 같이 추출된 DoG 영상에서 같은 scale에서 주변값(8개), 상/하 scale의 주변값(9+9개) 총 26개 점을 비교해서 최대값을 특징점으로 한다.
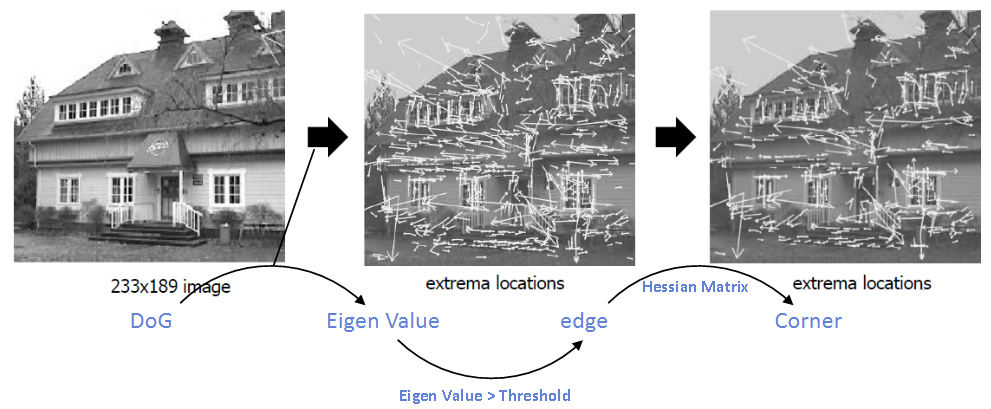
(3) Eliminate edge on Harris response function
(4) Orientation(Rotation)에 불변 → Rotation 보정(Normalization)
: Peak Point 찾기 : 전체 Gradient 계산 → Histogram 생성(방향정보에 따라) → 이미지의 주 방향을 찾는다.
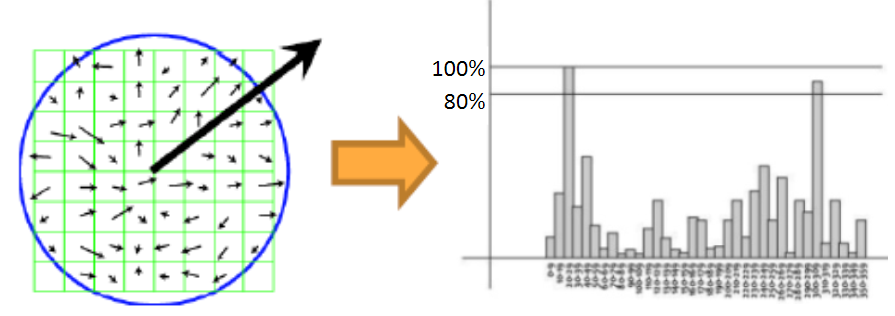
: 위 그림에서 80%를 기준으로 이상이 되는 각도를 주축으로 하는 descriptor를 생성
→ 여기서 80%이상이 n개라면 n개의 descriptor가 생성된다.
(5) Compute feature signature : Gradient histogram을 그대로 이용
: 16x16 window를 4x4로 zone별로 쪼갠다.
→ 8개의 방향 vector x16 = 128개의 방향벡터 (=128 dimension)
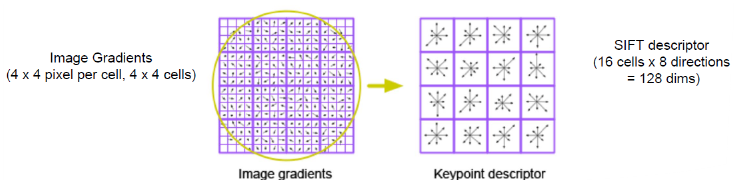
→ keypoint : x, y scale orientation(Covarient), feature vector(Invatient)
※ SIFT를 다시 정리하면 아래와 같다.

SURF(Speed-up Robust Features)
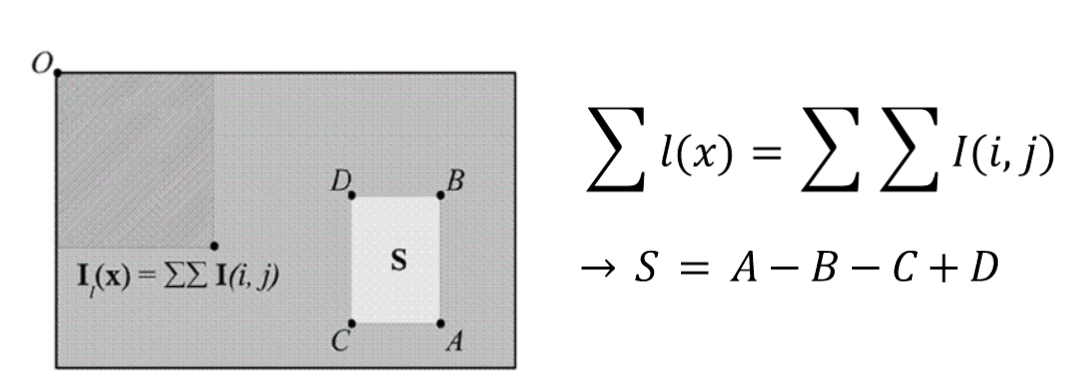
- Haar 필터와 적분영상(Integral Image)을 사용 → 계산량을 줄일 수 있다.
- Blurring, rotation에 효과적, 뷰포인트, 밝기 변화에 약하다
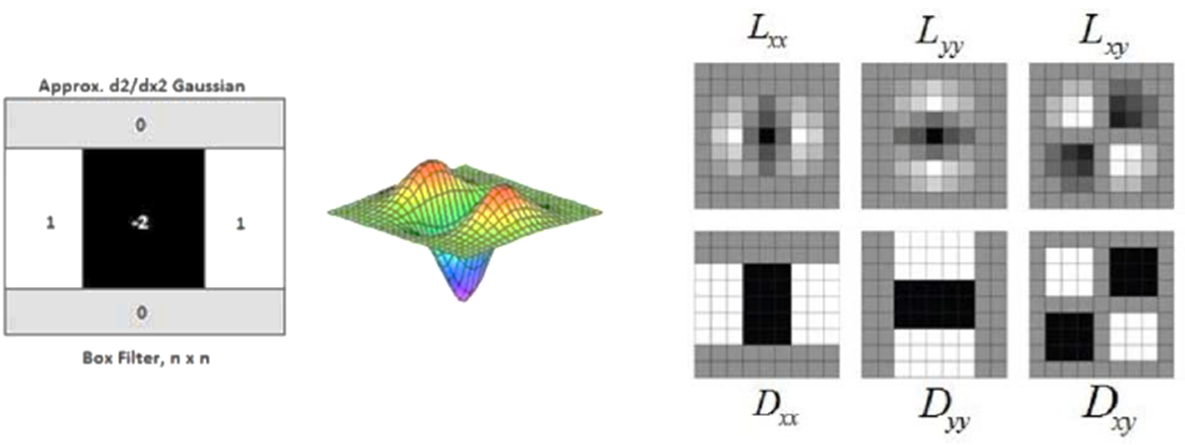
- 계산 효율을 위해 Hessian-Laplacian을 사용한다.(LoG를 근사화)
· Filtering/Convolution → Interest point detection
· Haar wavelet → Descriptor vector
- 적분영상(Integral Image)
- Hessian Matrix (Laplacian of Gaussian을 근사화) : 정확성이 좋음
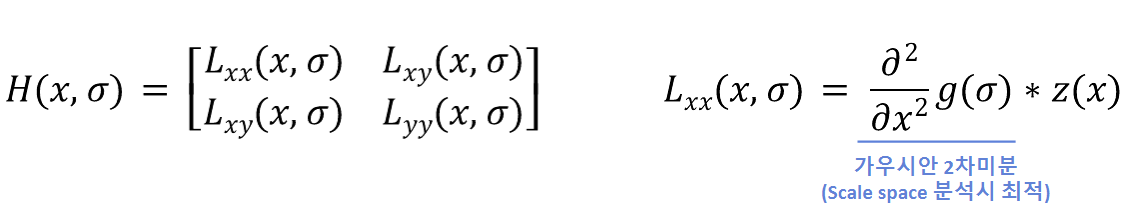
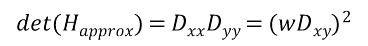
: det(H_approx)가 최대가 되는 값 → extreme 값을 찾는다.
: w → descrete한 필터로 표현시 보정. w→0.9(실험값)
→ (1) det(H_approx)가 음수이고 eigen value가 서로 다른 부호일 경우? → 극값이 아님(계산 불필요)
(2) det(H_approx)가 양수이고 eigen value가 같은 부호일 경우? → 극값으로 판단한다.
· SIFT와의 차이
- SIFT는 영상을 octave가 올라갈수록 Downsampling 시키며, Scale 적용과정에서 연산속도가 느려진다.(매번 Gaussian filter를 적용)
- SURF는 영상은 고정된 상태로 Filter의 사이즈만 변화한다.(이미지가 이미 적분영상이 되어있기 때문)
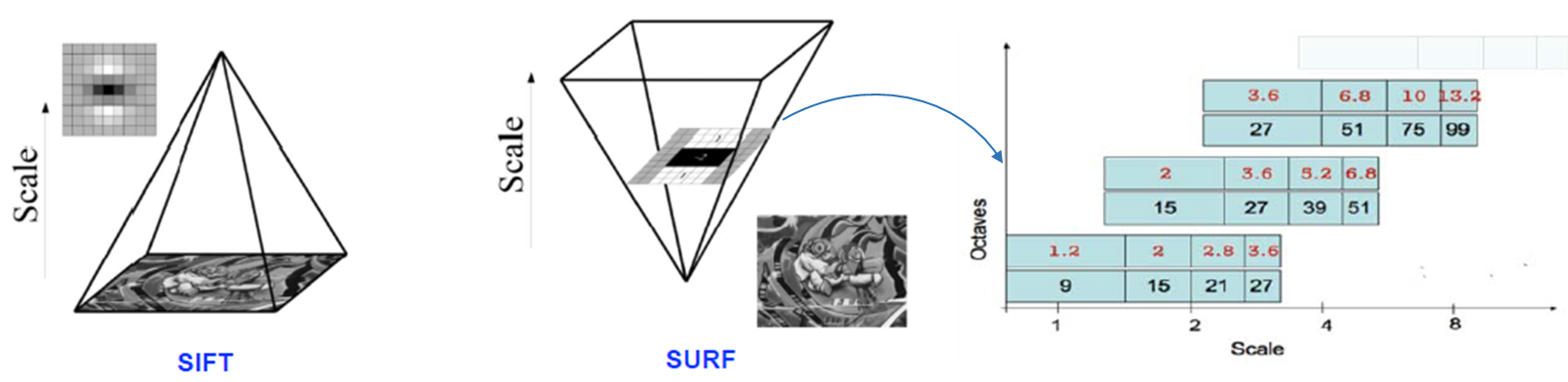
· Orientation assignment → Rotation에 Robust, 주축을 찾아 고정
- 아래 그림의 순서에 따라 수행한다.

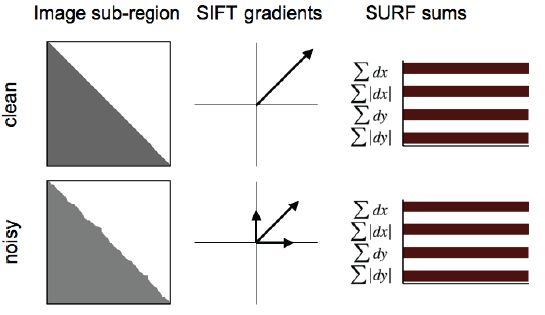
- SURF는 SIFT보다 약 3배정도 빠른 특징이 있으며, 아래 그림과 같이 noise에도 Robust하다.
HOG(Histogram of Orient Gradient)
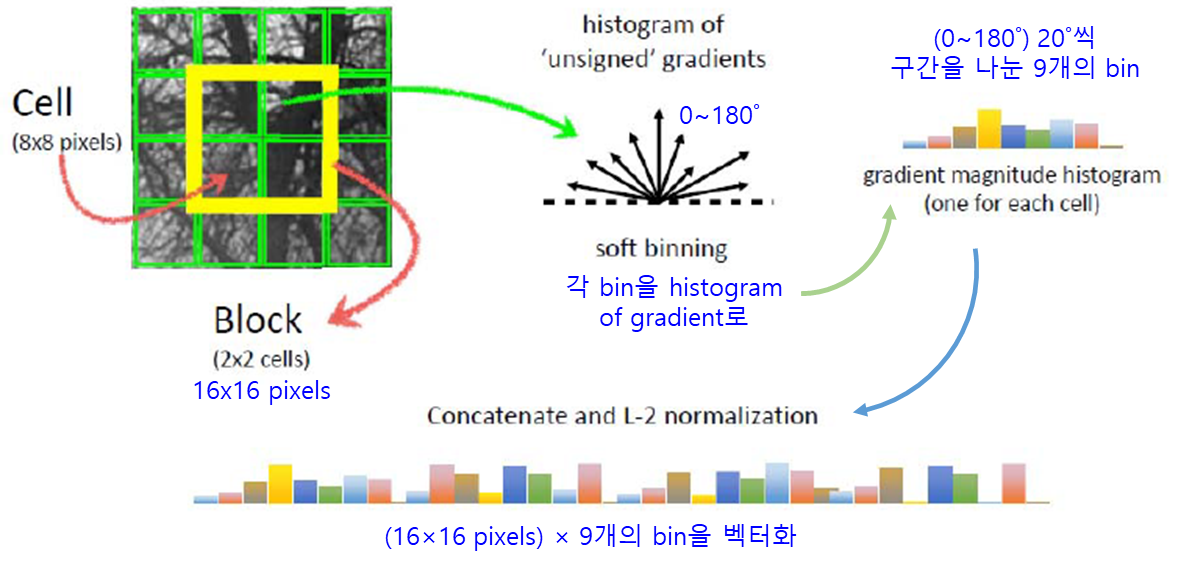
· HOG의 수행
① gradient 측정
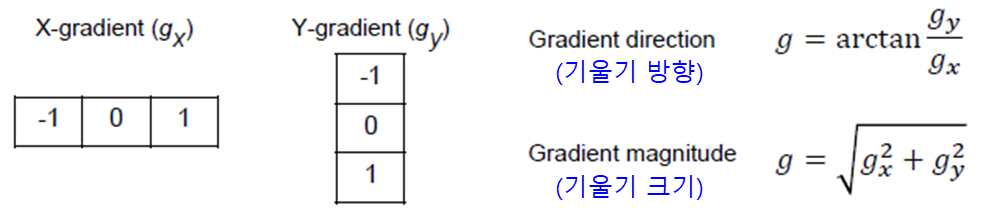
② 8×8 cell의 Histogram of gradient 계산

③ Blcok normalization
: 각 cell(cell1~cell4)을 모두 더한 후 ∑v_ij로 나누어 Normalize
→ 1 block vector = 4cells × 9normalized elements
④ Calculate Hog Vector

BRIEF(Binary Robust Independent Elementary Features)
- 일단 어떤 방법을 쓰던지 특징점을 찾고 이를 어떻게 기술할지
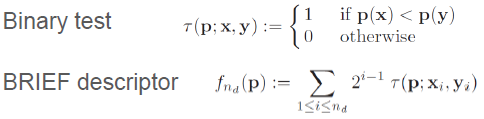
- Binary test(Pair 비교)
: 관심점을 기준으로 길게 cross비교하는 것이 효과적
: 주변의 pair Hamming distance 값을 이용 (*참고. SIFT는 주변의 gradient를 이용)
*Hamming Distance(XOR)
ex) ① 1 0 1 1 0 1 1 0 1
② 1 0 1 0 1 1 1 0 1 → ①과 ②는 2개의 값이 다름 → Hamming distance = 2

- BRIEF의 장점 : Compact, 계산이 쉽고 연산이 빠르다. 인식률이 좋다.
- BRIEF의 단점 : Pair를 이용하기 때문에 이미지의 변형, 왜곡에 약하다.(Rotating, Scaling)
ORB(Oriented FAST and Rotated BRIEF)
- SIFT와 SURF의 장점을 모아놓은 OpenCV
- FAST(특징점 추출), BRIEF(특징점 기술) + Oriented(BRIEF의 Rotation에 대한 단점 보완)
- Intensity centroid(무게중심) for corner orientation

- Image moment
: 윤곽선을 가진 픽셀을 대상으로 사용, shape, scale, rotation에도 강함

- Direction

- ORB 알고리즘의 순서
(1) FAST : Keypoint 찾기
(2) Harris corner detection : N개의 best points 선택
(3) 무게중심과 방향성 추가
(4) BRIEF
(5) Greedy algorithm : 방향에 맞는 최적의 square model을 찾는다.
(6) Descriptor 활용
*FAST Corner detector

- Sampling pair의 특성
(1) 서로 상관성이 적도록(Uncorrelation)
(2) 특징과 분산이 크도록(Greedy algorithm, High variance - more discriminative)
'DataScience > 컴퓨터비전' 카테고리의 다른 글
| 컴퓨터 비전 :: Stereo Vision (0) | 2023.06.20 |
|---|---|
| 컴퓨터 비전 :: Feature Matching (0) | 2023.06.19 |
| 컴퓨터 비전 :: Local Feature Detection (1) | 2023.06.17 |
| 컴퓨터 비전 :: Image Pyramids (0) | 2023.06.16 |
| 컴퓨터 비전 :: Linear Filters(Cross-correlation, Convolution) (0) | 2023.06.15 |




댓글