
머신러닝 :: 7. Naive Bayesian
Naive Bayesian
· 예측 결과에 대한 확률이 주어졌을 때, input 인자들이 서로 독립(Independent)이라고 가정하는 방법이다.
· Naive : 느슨한, Overfitting을 피하는 컨셉?
→ 수행이 매우 쉬운 특징이 있으며 Dataset이 아주 적지만 않다면(Moderate or large training set), 큰 Dataset이 아니더라도 양호한 예측결과를 얻어내는 방법이다. (*각 class의 속성들이 Conditionally independent할 때 사용 가능)
→ 하지만 만약 input class이 correlation이 크거나, 데이터셋이 일정 수보다 작다면 성능이 떨어지는 문제가 있다.
→ 본 방법은 진단(Diagnosis)이나 문서의 텍스트 분류(Spam 메일 분류) 등에 잘 사용될 수 있다.
Naive Bayesian Classification의 표현
- target function f:X→Y라고 가정하고, search space x는 (a_1, a_2, ..., a_n)일 때, 아래 f(x)를 만족하는 v를 찾는 식으로 나타낼 수 있다.
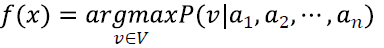
· 그리고 위 식은 베이즈 정리(Bayes' Theorem)에 의해 아래와 같이 표현이 가능하다.
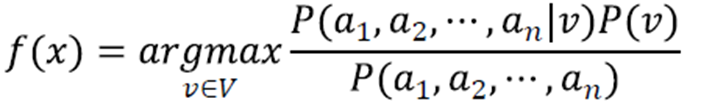
· 식을 최대로 하는 v값을 찾는 것이기 때문에 v값과 관련이 없는 분모부분은 소거가 가능하다.

· Naive Bayesian은 input인자들이 서로 독립(Independent)이라고 가정하기 때문에 위 식은 아래와 같이 간략하게 변환이 가능하다. 이제 각 확률의 값을 계산하고 최적의 클래스 분류를 하는 v값을 선택하면 된다.

· 아래의 예시는 Outlook, Temp, Humidity, Wind에 대한 테니스 Play여부에 대한 확률을 구하는 식이다.
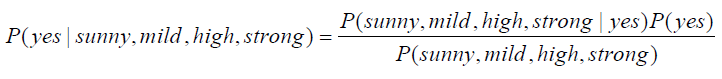

· 위 식의 분자 부분은 각 input 인자(Outlook, Temp, Humidity, Wind)가 독립이라고 가정하면 아래와 같이 변환이 가능하다.
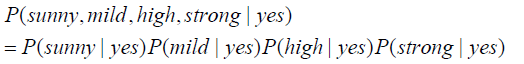
· 그리고 분모부분은 아래와 같이 미지수 α로 둔다.
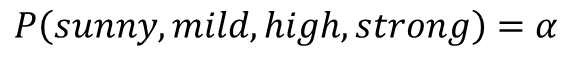
· 이제 두 식은 아래와 같이 비교할 수 있으며, 미지수 α는 서로 같기때문에 분자부분만 비교하여 더 큰 쪽을 예측하면 된다.

· 참고로 미지수 α를 구하려면 아래와 같이 총 확률의 합은 1이라는 확률의 특성을 활용하여 구할 수 있다.
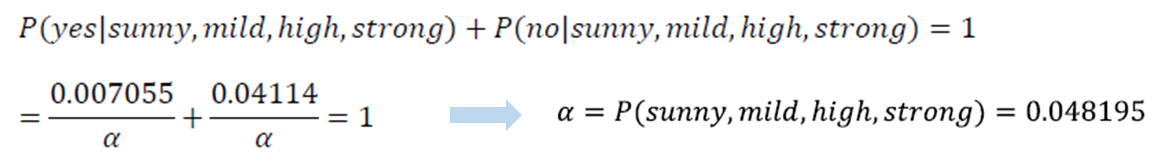
Naive Bayesian Method가 잘 동작하지 않는 경우
· Naive Bayesian은 각 클래스별로 적어도 일정 수 이상의 data를 포함하고 있어야 한다.
아래의 예시를 보면 Condition Attribute중 하나인 'Outlook = Sunny'의 데이터가 없어 확률이 0이되는 경우가 발생했다고 가정해보자.

· Naive Bayesian Classifier를 통해 예측시 아래와 같이 확률이 0이 되는 경우가 발생한다.

· 이러한 문제를 해결하기 위해서는 확률이 0이 되는 부분을 매우 작은 수로 대체하여 예측하는 방법이 있다.

'DataScience > 머신러닝' 카테고리의 다른 글
| 머신러닝 :: Support Vector Machine (0) | 2023.04.28 |
|---|---|
| 머신러닝 :: Constrained Optimization (0) | 2023.04.27 |
| 머신러닝 :: Logistic Regression, Gradient Descent Method (1) | 2023.04.25 |
| 머신러닝 :: New Interpretation of Linear Regression(MLE) (0) | 2023.04.24 |
| 머신러닝 :: Model Optimization, Evaluation, Cross Validation (0) | 2023.03.21 |




댓글