
머신러닝 :: 4. Model Analysis(Optimization, Evaluation, Cross Validation)
Overfitting) vs Generalization
· 아래와 같이 주어진 데이터가 있다고 가정했을 때, 이 데이터를 잘 예측할 수 있는 회귀 방정식을 찾아내려면 어떻게 해야할까?
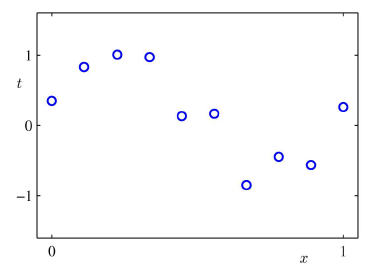
· 에러를 가장 적게 내는 것이 정말 좋은 방정식일지는 고민해봐야 한다. 아래 4개의 그림을 보면 왜인지 알 수 있다.
· 차수가 3차원까지는 데이터를 완벽하게 따라가지는 않더라도 유사하게 예측했다고 볼 수 있을 것이다. 그런데 9차원까지 간다면? 문제가 발생한다.

· 이러한 예측은 주어진 데이터에는 완벽하게 잘 들어맞지만, Unknown Data에는 예측 정확도(Prediction accuracy)가 떨어지는 경우가 발생하게 된다.
· 머신러닝의 목적은 무엇일까? 주어진 데이터만 잘 학습하는 것인가? 주어진 데이터를 기반으로 미지의 데이터를 가능한한 정확하게 예측하는 것인가? 아마도 후자일 것이다.
· 결국 차수(The order)가 증가할수록,모델의 복잡도(Complexity)도 증가하게 되고, 이로인해 기존 데이터(Given data)는 정확하게 학습할 수 있지만, 예측 정확도(Prediction Accuracy)는 무조건 증가하는 것은 아니다.
Model Evaluation, 좋은 모델을 찾는 것
· 모델을 평가하는 효과적인 방법으로는 아래 두 가지를 활용할 수 있다.
① Based on Training & Testing data set
② Cross-Validation
1) Training Set and Test Set
: 주어진 데이터를 트레이닝 셋, 테스트 셋(ex. 7(training) : 3(test))으로 나눈다. 이 때, 서로 겹치면 안되고 가능한한 서로 독립적(영향을 주지 않는)이어야 한다. 트레이닝 셋은 모델을 생성하는 데 사용되고, 테스트 셋은 생성한 모델을 평가한다. 이를 통해 테스트 셋에서 최고의 성능을 내는 모델을 선택한다.
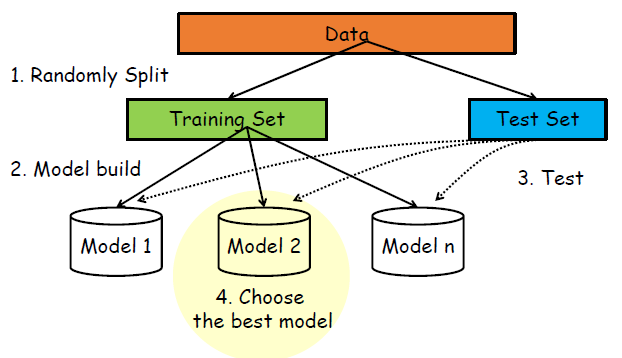
: 일반적으로 알려져 있는 비율은 트레이닝(70%), 테스트(30%)이나, 테스트 셋과 트레이닝 셋의 비율은 상황, 또는 데이터 수, 사용자의 경험에 따라 다르게 설정될 수 있다. 즉, 정해진 것은 없다.
| 장점 | 단점 |
| · 간단하고, 쉽다 | · 테스트셋은 모델을 만드는데 사용되지 않기 때문에 데이터의 낭비가 발생한다. · 데이터가 랜덤하게 분리된다. (데이터가 어떻게 분리되는지에 따라 모델 평가가 극명하게 바뀐다.) → 보완책? Cross-Validation |
2) Cross Validation
· 데이터 분리에 따른 평가 상이 문제를 해결하기 위해 Cross Validation을 적용할 수 있다. Cross Validation에는 k-fold cross validation이 많이 사용되고 있다.
· k-fold Cross Validation : k개의 fold로 데이터를 분리한다. 이 때, 각 fold에는 다른 fold와 중복되는 데이터가 없어야 한다.
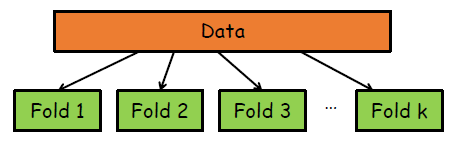
· 그리고 k-1개의 training set, 1개의 test set을 선정하고 모델을 만든다.

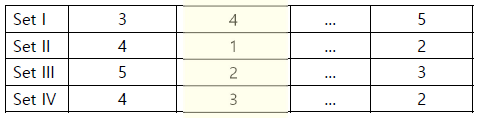
· 각 모델을 통해 산출된 모델 중 가장 좋은 성능을 냈던 모델을 선택한다.
· 주로 모델은 5-fold, 10-fold가 많이 사용되며, k가 증가할 수록 모델에 따른 변화/차이(Variance)는 줄어든다.
· data set은 k개의 subsets으로 나뉘고, holdout method는 k회 반복된다.
· k가 증가할수록 variance(변동량)는 감소한다.
| 장점 | 단점 |
| · 데이터가 어떻게 분리되었는지에 대해 덜 의존적이다. · 모든 데이터가 한번은 테스트셋으로 사용되고, k-1번은 트레이닝 셋으로 사용된다. (데이터 낭비를 줄인다.) |
· 모델을 만들고 최적의 모델을 만드는 데 까지 시간이 많이 소요된다. (특히, 굉장히 큰 데이터셋에는 사용하기 어렵다.) |
Variation
· No fixed folds and Random Division
: fold로 쪼개지 않고, 데이터를 랜덤하게 test set, training set으로 k번 나누어 사용하는 방식
(↔ 기존 Regular CV : Split into folds and shuffling folds)
· LOOCV(Leave-one-out Cross Validation)
: 데이터 하나만 test set, 나머지 전체는 training set으로 하여, 총 데이터가 n개이면 n번을 반복하는 방식
(데이터가 너무 많으면 사용하기 어렵다.)
'DataScience > 머신러닝' 카테고리의 다른 글
| 머신러닝 :: Logistic Regression, Gradient Descent Method (1) | 2023.04.25 |
|---|---|
| 머신러닝 :: New Interpretation of Linear Regression(MLE) (0) | 2023.04.24 |
| 머신러닝 :: Linear Regression(선형 회귀식 풀이법, SLE) (0) | 2023.03.20 |
| 머신러닝 :: k-NN for Classification, Regression (0) | 2023.03.20 |
| 머신러닝 :: 개요, 머신러닝 딥러닝 차이 (0) | 2023.03.20 |




댓글