
머신러닝 :: 1. Introduction to Machine Learning
· 인공지능(Artificial Intelligence) : 인간의 지적능력(계산, 학습 등)을 컴퓨터를 통해 구현하는 기능(모든 자동화)
· 머신러닝(Machine Learning) : 데이터로부터 의사결정을 위한 패턴을 기계가 스스로 학습
· 딥 러닝(Deep Learning) : 인공신경망 기반의 모델로, 비저어형 데이터로부터 특징 추출/판단(=Deep Neural Network)
머신러닝이란?
· "To improve the perfomance of programs base on given data, previous result, or experiences"
· 전통적 프로그래밍은 규칙을 사람이 수정 해야 했지만, 머신러닝은 기계가 스스로 규칙을 수정 한다.
머신러닝의 장점
· 프로그래밍 시간을 줄이는 도구로서
· 특정 집단의 사용자에게 잘 맞는 것을 제공하고
· 문제를 해결하기 위한 알고리즘이 없거나 어려운 경우 해결하고
· 문제 해결을 위한 수리 과학적 사고만 하던 것에서 자연 과학적 사고를 하도록 만든다.
머신러닝의 학습방법(3가지)

1) 지도학습(Supervised Learning)
· 데이터에 대한 레이블(Label), 즉 명시적인 정답이 주어진 상태에서 컴퓨터를 학습시키는 방법론
· [데이터(data), 레이블(Label)] 형태로 학습
· Labeled data, Direct feedback, Predict outcome/future
· training set으로 학습이 끝나면 label이 지정되지 않은 test set을 이용해서 얼마나 정확히 예측하는가 측정
· 예측하는 결과값이 이산값이면 Classification(분류) 문제, 연속값이면 Regression(회귀) 문제
2) 비지도학습(Unsupervised Learning)
· 데이터에 대한 레이블(Label), 즉 명시적인 정답이 주어지지 않은 상태에서 컴퓨터를 학습시키는 방법론
· [데이터(data)] 형태로 학습
· No labels, No feedback, "Find hidden structure"
· 데이터의 숨겨진(Hidden) 특징(Feature)이나 구조를 발견하는데 사용된다.
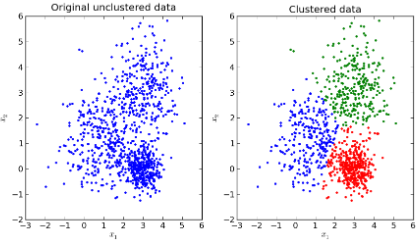
· 데이터가 무작위로 분포되어 있을 때 비슷한 특성을 가진 세가지 부류로 묶는 클러스터링(Clustering) 알고리즘을 예로 들 수 있다.
3) 강화학습(Reinforcement Learning)
· 주어진 환경(State)에 대해 어떤 행동(Action)을 취하고 이로부터 어떤 보상(Reward)을 얻는가를 이용하여 학습
· Decision process, Reward system, Learn series of actions
· 에이전트는 보상(Reward)을 최대화(Maximize)하도록 학습을 진행한다.
· 강화학습은 일종의 동적인 상태(Dynamic environment)에서 데이터를 수집하는 과정까지 포함하는 알고리즘이다.

머신러닝의 특징
· 머신러닝은 스스로 규칙을 찾는다. 여기서 규칙은 가중치(Weight)와 절편(Bias)라고 할 수 있으며, 가중치와 절편을 가진 수식을 모델(Model)이라고 한다.
· 모델 학습 : 라벨이 있는 데이터로부터 올바른 가중치와 절편(or 편향)을 학습/결정하여 평균적으로 작은 손실을 갖는 모델을 찾는 것
· 지도학습에서 머신러닝 알고리즘은 다양한 예를 검토하고 손실*을 최소화하는 모델을 찾아봄으로써 모델을 만들어내는데, 이 과정을 경험적 위험 최소화(ERM, Empirical Risk Minimization)이라고 한다.
*손실 : 모델의 예측이 얼마나 잘못되었는지를 나타내는 수. 예측이 완벽하면 손실은 0, 그렇지 않으면 손실은 증가
· 모델 학습은 손실함수(Loss function)을 정의하고 이를 최적화(최소화)하는 가중치와 절편을 찾아낸다.
모델을 어떻게 학습시키는가?
* Squared Loss(L2 Loss)
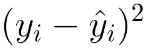
* Mean Squared Error(MSE)

※ 모델 학습 참고 사이트 (※ Google Developers_Machine Learning 기초과정 Crash Course : 링크)
딥러닝이란
· 머신러닝 알고리즘 중 하나인 인공신경망(Artificial Neural Network)으로 만든 것
· 복잡한 문제를 해결위해 인공신경망을 다양하고 깊게 쌓은 것을 딥뉴럴네트워크(Deep Neural Network)라고 하고 이를 일반적으로 딥러닝이라고 한다.
· 입력층, 은닉층, 출력층으로 구분되며, 보통 Hieen layer가 8층 이상인 것을 Deep Learning이라고 한다.
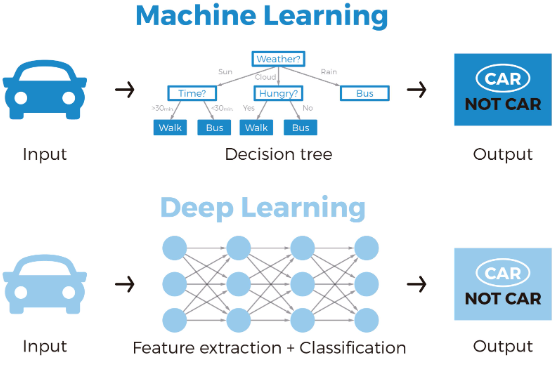
· 아래 그림처럼 Feature engineering이 필요한 일부 머신러닝(의사결정나무 등)과 달리, 딥러닝은 Feature engineering이 필요하지 않으며, 가중치에 따라 입출력에 맞는 Network 구조를 만든다. 하지만, 왜 그런지에 대한 설명이 부족한 '약점'이 존재한다.
· 인공신경망을 구성하고 있는 퍼셉트론(Perceptron)은 아래 그림과 같이 인체 내의 뉴런(Neuron)과 같이 구성된다.
· 각 Inputs들은 가중치(Weight)와 편향(Bias)를 통해 계산된 Weighted sum(Σ)이 되고, 퍼셉트론에서는 이 값이 Threshold(=Hillock)을 넘어갈 경우 Output이 전달된다.

'DataScience > 머신러닝' 카테고리의 다른 글
| 머신러닝 :: Linear Regression(선형 회귀식 풀이법, SLE) (0) | 2023.03.20 |
|---|---|
| 머신러닝 :: k-NN for Classification, Regression (0) | 2023.03.20 |
| 머신러닝 :: 머신러닝 추천 서비스 구현_데이터 필터링, 쿼리셋 다루기 _TIL67 (1) | 2022.12.08 |
| Web 개발 :: 프로젝트 조회수, Permission, Dataframe, 머신러닝_TIL66 (0) | 2022.12.07 |
| 파이썬 웹 프로그래밍 :: 10월 셋째주 WIL #07 (0) | 2022.10.20 |




댓글