■ JITHub 개발일지 67일차

□ TIL(Today I Learned) ::
머신러닝 추천 서비스 구현_데이터 필터링, 쿼리셋 다루기
1. 데이터 필터링
- 특정 문자열과 일치
filter = df['col_name'] == 'check_data'
result = df[filter]- 특정 문자열 포함
filter = df['col_name'].str.contains('str1|str2|str3')
result = df[filter]- 특정 문자열을 제외
filter = df['col_name'].str.contains('str1|str2|str3')
result = df[~filter]※ 쿼리셋 안에서 특정 문자 포함여부 확인(__contains를 사용한다.)
for i in range(0, 12):
pick = Place.objects.filter(place_address__contains=CHOICE_CATEGORY[choice_no-1][1],category=CHOICE_CATEGORY[i][1]).first()
place_list.append(pick.id)
2. 쿼리셋 정렬 (order_by)
User.objects.all().order_by('created_at') # 오름차순
User.objects.all().order_by('-created_at') # 내림차순3. Django ORM에서 쿼리셋 커스텀 정렬할 경우 (*참고 링크)
from django.db.models import Case, When
# pk_list에 적힌 순서대로 정렬하고자 할 경우
pk_list = [1, 4, 3]
preserved = Case(*[When(pk=pk, then=pos) for pos, pk in enumerate(pk_list)])
queryset = MyModel.objects.filter(pk__in=pk_list).order_by(preserved)4. json파일을 DB에 적용하고자 하는데 아래와 같이 UTF-8 코덱과 일치하지 않아 Decode가 불가하다는 에러가 발생했다.
python manage.py loaddata places.jsonUnicodeDecodeError: 'utf-8' codec can't decode byte 0xb2 in position 62: invalid start byte- 해결방법은 간단했다. 메모장에서 해당 파일을 열고 다른 이름으로 저장시 아래 인코딩을 UTF-8로 변경하면 된다.
5. 쿼리셋 (*참고 링크)
아래는 오늘 만들었던 취향선택을 위한 코드이다.
# views.py
##### 취향 선택 #####
class PlaceSelectView(APIView):
#맛집 취향 선택(리뷰가 없거나, 비로그인 계정일 경우)
def get(self, request, choice_no):
place_list = []
# 지역 선택일 경우
if choice_no > 12:
place_list = []
for i in range(0, 12):
pick = Place.objects.filter(place_address__contains=CHOICE_CATEGORY[choice_no-1][1],category=CHOICE_CATEGORY[i][1]).first()
place_list.append(pick.id)
preserved = Case(*[When(pk=pk, then=pos) for pos, pk in enumerate(place_list)])
place = Place.objects.filter(id__in=place_list).order_by(preserved)
serializer = PlaceSelectSerializer(place, many=True)
return Response(serializer.data, status=status.HTTP_200_OK)
# 음식 선택일 경우
else:
if (choice_no == 3)|(choice_no == 6)|(choice_no == 12):
place_list = []
pick1 = Place.objects.filter(category=CHOICE_CATEGORY[choice_no-1][1])[0:3]
pick2 = Place.objects.filter(category=CHOICE_CATEGORY[choice_no-2][1])[0:3]
pick3 = Place.objects.filter(category=CHOICE_CATEGORY[choice_no-3][1])[0:3]
pick = (pick1|pick2|pick3)
serializer = PlaceSelectSerializer(pick, many=True)
return Response(serializer.data, status=status.HTTP_200_OK)
else:
place_list = []
pick = Place.objects.filter(category=CHOICE_CATEGORY[choice_no-1][1])[0:12]
print(pick)
serializer = PlaceSelectSerializer(pick, many=True)
return Response(serializer.data, status=status.HTTP_200_OK)- 쿼리셋의 첫번째 항목만 가져올 경우는 .first()를 사용하고, 쿼리셋의 0~x인덱스까지 가져올 경우 위의 코드와 같이 인덱스 슬라이싱으로 가져올 수 있었다.
- 또, 쿼리셋 병합이 가능한데 위의 pick = (pick1|pick2|pick3}과 같이 '|' 문자를 사용하거나, union 함수를 이용하기도 한다.
6. 가장 짜증났던 오류
- 위의 코드를 작성하면서 다양한 오류를 접했다.
- 예를들면 아래 오류. 'NoneType' object has no attribute 'id'
- 분명히 위에 30~147과 같이 id를 읽어오고 있는데 왜 Nonetype이라는거지?
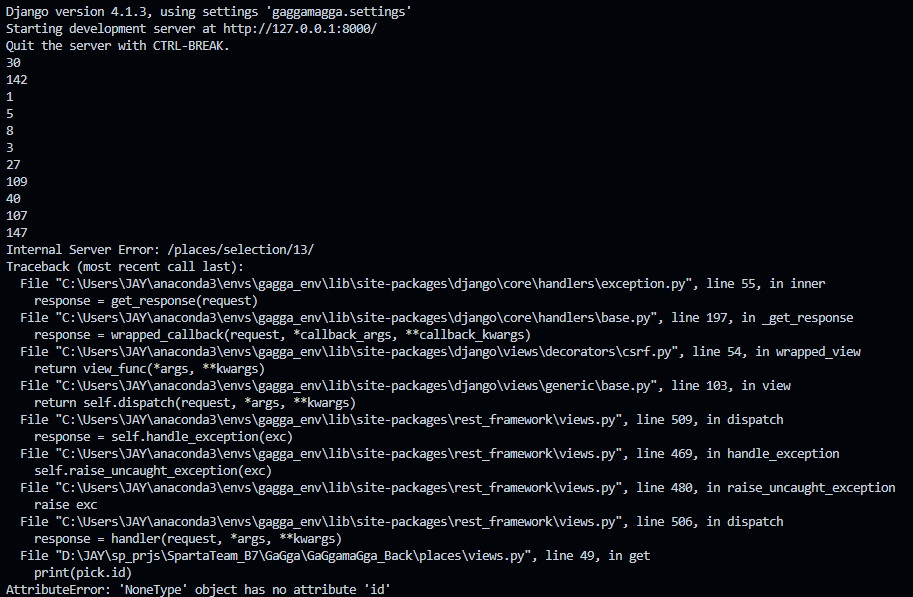
쿼리셋을 다시 뽑아보니 아래와 같이 None이 맨 마지막에 하나 숨어있었다. 인덱스가 out of range된 탓으로, 인덱스를 다시 조정하고 나서 해결할 수 있었다.

'DataScience > 머신러닝' 카테고리의 다른 글
| 머신러닝 :: k-NN for Classification, Regression (0) | 2023.03.20 |
|---|---|
| 머신러닝 :: 개요, 머신러닝 딥러닝 차이 (0) | 2023.03.20 |
| Web 개발 :: 프로젝트 조회수, Permission, Dataframe, 머신러닝_TIL66 (0) | 2022.12.07 |
| 파이썬 웹 프로그래밍 :: 10월 셋째주 WIL #07 (0) | 2022.10.20 |
| 머신러닝 :: 딥러닝 MNIST 실습_과일 종류 예측 (0) | 2022.10.14 |




댓글