
캐글(Kaggle) 선형회귀 분석 : Single-variable linear regression, optimizer(Adam, SGD)
1. 캐글(Kaggle) 데이터셋 준비하기
1) Salary 데이터셋을 활용한 선형회귀 예측
· 먼저 아래 사이트에서 csv 데이터를 받아와서 분석코드를 짰다.

· 데이터 모습은 간단히 아래와 같았다.
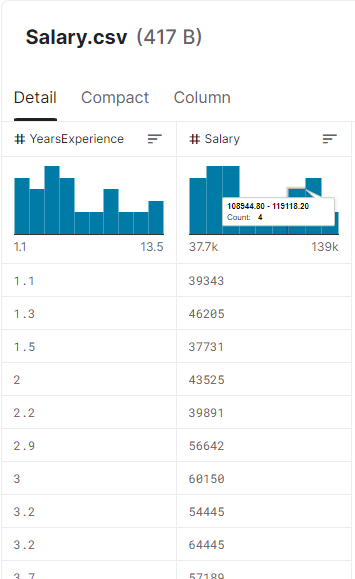
· 데이터를 받아오기 위해 환경설정을 하고 아래와 같이 자료를 받아 압축을 풀고 셋팅하였다.
import os
os.environ['KAGGLE_USERNAME'] = 'username' # username
os.environ['KAGGLE_KEY'] = 'key' # key
!kaggle datasets download -d rsadiq/salary
"""
Downloading salary.zip to /content
0% 0.00/392 [00:00<?, ?B/s]
100% 392/392 [00:00<00:00, 306kB/s]
"""
!unzip salary.zip
"""
Archive: salary.zip
inflating: Salary.csv
"""· 분석을 위해서 사용할 클래스와 모듈들을 미리 임포트해온다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split· 먼저 데이터셋을 로드한다.
# 데이터셋 로드
df = pd.read_csv('Salary.csv')
# 모델 확인
# df.head(5)
# print(df.shape)
# sns.pairplot(df, x_vars=['YearsExperience'], y_vars=['Salary'], height=4)· 모델을 넘파이 어레이로 만들고, shape를 reshape를 통해 통일시켜준다.
x_data = np.array(df[['YearsExperience']], dtype=np.float32)
y_data = np.array(df['Salary'], dtype=np.float32)
# shape 확인
# print(x_data.shape)
# print(y_data.shape)
"""
(35, 1)
(35,)
"""
x_data = x_data.reshape((-1, 1))
y_data = y_data.reshape((-1, 1))
# shape 확인
# print(x_data.shape)
# print(y_data.shape)
"""
(35, 1)
(35, 1)
"""· 학습 데이터(80%)와 검증 데이터(20%)를 분할한다.
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2000)
# train, test shape 확인
# print(x_train.shape, x_val.shape)
# print(y_train.shape, y_val.shape)· 모델을 구성해주었다. 처음에 optimizer를 Adam을 선택했다.
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.01))· 이제 데이터를 fit을 통해 학습시킨다.
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val),
epochs = 100
)· 위와 같이 loss값이 엄청 크게 결과값으로 출력된다.

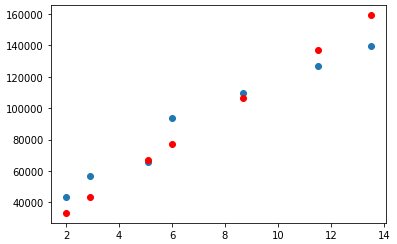
· 예측값을 시각화해보면 아래와 같이 확인된다. 예측값의 loss를 줄이기 위해 다른 방법이 필요해 보였다.
y_pred = model.predict(x_val)
plt.scatter(x_val, y_val)
plt.scatter(x_val, y_pred, color='r')
plt.show()
· 기존의 optimizer가 Adam으로 설정이 되어있던 것을 SGD(Stochastic gradient descent)로 변경해주었다.

그러자 loss값이 아직 크지만 이전에 비해서는 눈에 띄게 줄었다. 실제 그래프를 보아도 선형성을 확인할 수 있게 되었다.
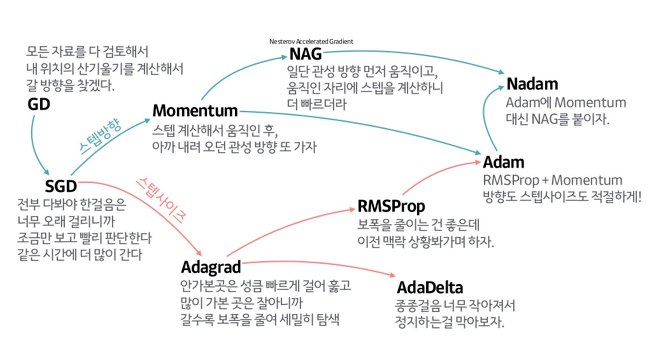
optimizer는 GD, SGD 뿐 아니라 다양한 종류들이 있고, 각각의 성격들도 속도, 정확성 등이 모두 조금씩 다르다.
아래 참고 링크에 따르면 Adam은 방향성, 스텝 사이즈를 고려하는 새로운 Optimizer이고, Stochastic Gradient Descent는 기존의 Gradient Descent의 속도를 개선한 Optimizer이다. 그러나 최적의 값을 찾아가는 방향이 뒤죽박죽이고, 스텝 사이즈를 정하기가 어려운 단점이 있는 Optimizer이다. 이러한 성격으로 볼 때 Adam일 때 더 최적값을 잘 찾아야 하는데, 이 문제에서는 그렇지 않다. 해당 문제에 대해 추가적인 연구가 필요할 것으로 보인다.
Referencecs
- 자습해도 모르겠던 딥러닝, 머리속에 인스톨 시켜드립니다
- Machine Learning FAQ
- An overview of gradient descent optimization algorithms
- 딥러닝(Deep learning) 살펴보기
'DataScience > 머신러닝' 카테고리의 다른 글
| 머신러닝 :: 머신러닝 모델(SVM, KNN, 의사결정 나무, 랜덤 포레스트) (0) | 2022.10.12 |
|---|---|
| 머신러닝 :: 논리 회귀(Logistic Regression) 개념 (0) | 2022.10.11 |
| 머신러닝 :: 캐글(kaggle) 데이터셋을 활용한 선형회귀 실습 (1) | 2022.10.11 |
| 머신러닝 :: 선형회귀(Linear Regression) 분석 실습(Tensorflow, Keras) (0) | 2022.10.11 |
| Web 개발 :: 파이썬 django 인스타그램 클론 코딩 완료, 머신러닝_TIL#27 (0) | 2022.10.10 |




댓글