
캐글(Kaggle) 선형회귀 분석 : Single/Multi-variable linear regression
1. 캐글(Kaggle) 데이터셋 준비하기
1) Kaggle 데이터셋 가져올 준비하기
① 캐글(Kaggle) 회원가입 → Account(계정)
② API - Create New API Token 클릭하여 kaggle.json 다운로드
③ 브라우저에서 json 파일을 열어 username 및 key 복사
④ 아래 코드에 자신의 username 및 key를 붙여넣어 환경변수 설정 실행
import os
os.environ['KAGGLE_USERNAME'] = '<username>' # 본인의 username
os.environ['KAGGLE_KEY'] = '<key>' # 본인의 key2) 광고 데이터셋 다운로드
① 원하는 데이터셋을 검색
② 우상단의 더보기(...)버튼 클릭 → [Copy API command] 버튼 클릭
③ 셀에 붙여넣고 실행(코랩에서는 맨 앞에 느낌표'!'를 붙여야 한다.)
# ex
!kaggle datasets download -d ashydv/advertising-dataset④ 데이터셋 압축 해제
# 압축 해제
!unzip /content/advertising-dataset.zip
2. 캐글(Kaggle) 데이터로 선형회귀 실습하기(1)
광고 데이터 예측 (Single-variable linear regression)
- TV 광고 금액으로 Sales 예측하기
· 케라스 기본 환경 셋팅하기(matplotlib, seaborn - 그래프 그릴 때 사용, train_test_split - 트레인셋, 테스트셋 분리)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split· 데이터셋 로드
df = pd.read_csv('advertising.csv')
df.head(5)
· 데이터셋 크기 확인하기
print(df.shape)
"""
>>> (200, 4)
"""· 데이터셋 살펴보기
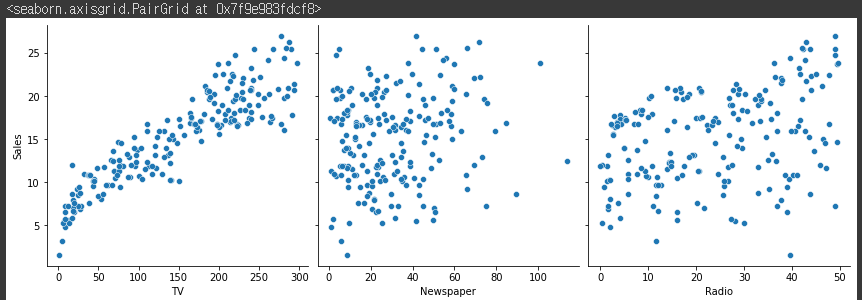
sns.pairplot(df, x_vars=['TV', 'Newspaper', 'Radio'], y_vars=['Sales'], height=4)
· 데이터셋 가공 : 아래 식을 보았을 때 shape이 맞지 않는 것을 확인할 수 있다. 아래 식의 reshape를 활용하여 통일화해준다.
x_data = np.array(df[['TV']], dtype=np.float32)
y_data = np.array(df['Sales'], dtype=np.float32)
print(x_data.shape)
print(y_data.shape)
"""
>>> (200, 1)
>>> (200,)
"""x_data = x_data.reshape((-1, 1))
y_data = y_data.reshape((-1, 1))
print(x_data.shape)
print(y_data.shape)
"""
>>> (200,1)
>>> (200,1)
"""· 데이터셋 분할 - 학습 데이터 80% 검증 데이터 20% (*random_state : 랜덤 변수 지정)
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape
"""
>>> (160, 1) (40, 1)
>>> (160, 1) (40, 1)
"""· 모델 설정(Sequential, dense(1)), 구성(optimizer = Adam)
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.1))· 모델 학습 (validation_data : 한 epoch이 끝날때 마다 검증된 결과를 보여준다.)
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
)· 검증 데이터로 예측하기 (정답값 y_val, 예측값 y_pred을 활용해 그래프를 보여준다,show())
y_pred = model.predict(x_val)
plt.scatter(x_val, y_val)
plt.scatter(x_val, y_pred, color='r')
plt.show()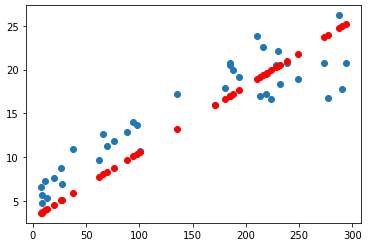
3. 캐글(Kaggle) 데이터로 선형회귀 실습하기(2)
광고 데이터 예측 (Multi-variable linear regression)
- TV, Newspaper, Radio 광고 금액으로 Sales 예측하기
· 사용환경 구성(single-variable 과 유사)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
df = pd.read_csv('advertising.csv')· Multi-variable에서는 x_data에 다중 입력값이 들어간다.(TV, Newspaper, Radio)
reshape시에더 x_data는 입력값이 3개이므로 (-1, 3)으로 입력한다.
x_data = np.array(df[['TV', 'Newspaper', 'Radio']], dtype=np.float32)
y_data = np.array(df['Sales'], dtype=np.float32)
x_data = x_data.reshape((-1, 3))
y_data = y_data.reshape((-1, 1))
print(x_data.shape)
print(y_data.shape)· 모델 학습 (validation_data : 한 epoch이 끝날때 마다 검증된 결과를 보여준다.)
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)· 모델 설정(Sequential, dense(1)), 구성(optimizer = Adam)
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.1))· 모델 학습
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
)
y_pred = model.predict(x_val)
print(y_pred.shape)
"""
(40, 1)
"""· 예측 그래프 확인 (TV 데이터 → 인덱스 0)
plt.scatter(x_val[:, 0], y_val)
plt.scatter(x_val[:, 0], y_pred, color='r')
plt.show()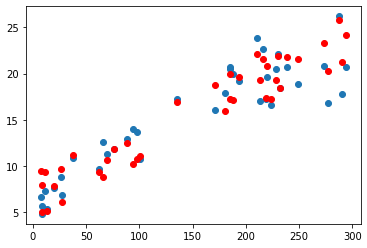
· 예측 그래프 확인 (Newspaper 데이터 → 인덱스 1)
plt.scatter(x_val[:, 1], y_val)
plt.scatter(x_val[:, 1], y_pred, color='r')
plt.show()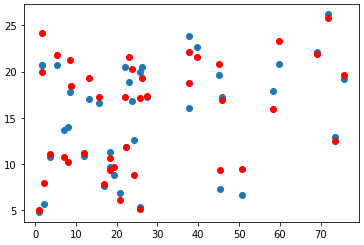
· 예측 그래프 확인 (Radio 데이터 → 인덱스 2)
plt.scatter(x_val[:, 2], y_val)
plt.scatter(x_val[:, 2], y_pred, color='r')
plt.show()
'DataScience > 머신러닝' 카테고리의 다른 글
| 머신러닝 :: 머신러닝 모델(SVM, KNN, 의사결정 나무, 랜덤 포레스트) (0) | 2022.10.12 |
|---|---|
| 머신러닝 :: 논리 회귀(Logistic Regression) 개념 (0) | 2022.10.11 |
| 머신러닝 :: 캐글(kaggle) 데이터셋을 활용한 선형회귀 실습(2) (0) | 2022.10.11 |
| 머신러닝 :: 선형회귀(Linear Regression) 분석 실습(Tensorflow, Keras) (0) | 2022.10.11 |
| Web 개발 :: 파이썬 django 인스타그램 클론 코딩 완료, 머신러닝_TIL#27 (0) | 2022.10.10 |




댓글