
머신러닝 선형회귀 분석(tensorflow, keras)
1. 텐서플로(Tensorflow)를 활용한 선형회귀 분석
·
· 먼저 텐서플로우를 아래와 같이 임포트 한다. Alias는 관례적으로 tf로 지정한다.
import tensorflow as tf· 텐서플로는 v1버전을 사용하기 위해 아래와 같이 호출하여 사용한다.
# tf.compat.v1.<함수명>
tf.compat.v1.disable_eager_execution()· 사용하려는 데이터셋을 정의한다. 아래에서 입력은 x_data, 출력은 y_data이다.
x_data = [[1, 1], [2, 2], [3, 3]]
y_data = [[10], [20], [30]]
· X, Y를 넣어줄 공간(placeholder)을 정의해준다. 괄호 안에는 데이터 형식(float32)과 모양(shape=[None, 2])을 지정해준다. shape에서 None은 배치사이즈, 그리고 뒤의 2는 입력값의 수로, x_data가 2개씩 들어가는 Multi-variable linear regression이기 때문에 2로 입력해준다. 마찬가지로 y_data는 출력값이 1개이므로 shape=[None, 1]로 지정한다.
X = tf.compat.v1.placeholder(tf.float32, shape=[None, 2])
Y = tf.compat.v1.placeholder(tf.float32, shape=[None, 1])· Weight와 bias는 variable로 지정하고, 초기 시작점은 랜덤하게 지정하기 위해서 random.normal을 사용한다. shape는 W는 (2,1)행렬, b는 (1,)행렬이다.
W = tf.Variable(tf.random.normal(shape=(2, 1)), name='W')
b = tf.Variable(tf.random.normal(shape=(1,)), name='b')· 가설은 선형회귀이므로 아래 식을 활용하여 hypothesis라는 식으로 생성한다.
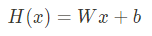
matmul은 입력된 값들을 서로 곱해주는 것을 말한다.
hypothesis = tf.matmul(X, W) + b· cost function은 mean squared error를 사용한 식이기 때문에 아래와 같이 식을 정의할 수 있다.
가설에서 정답값을 뺀(hypothesis - Y) 값의 제곱(square)한 것들의 평균(mean)을 낸다.
cost = tf.reduce_mean(tf.square(hypothesis - Y))· optimizer는 경사하강법(Gradient Descent Method)을 사용하기 때문에 GradientDescentOptimizer를 입력하고, learning_rate는 0.01스텝씩, cost를 최소화하는 방향으로 한다.
optimizer = tf.compat.v1.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)
· 세션(Session)은 텐서플로에서 사용하는 모든 변수들과 모든 그래프들을 저장하고 있는 저장소이다. 아래처럼 세션을 정의해주고, 모든 변수를 초기화한다. (sess.run(tf.compat.v1.global_variables_initializer()))
· with문 안에 for문을 통해 반복시킨다. 반복횟수는 50을 주었다. sess.run을 통해 계산을 진행한다. 계산에 사용되는 변수들을 넣어주고(cost, W, b, optimizer), feeding해야 하는 값을 각각 feed_dict에 딕셔너리 형태로 넣는다.
· 계산이 완료되면 각 step에 따라 cost를 print로 반환한다.
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
for step in range(50):
c, W_, b_, _ = sess.run([cost, W, b, optimizer], feed_dict={X: x_data, Y: y_data})
print('Step: %2d\t loss: %.2f\t' % (step, c))· 계산된 결과를 검증해볼 경우 아래와 같이 print문으로 검증할 수 있다.
print(sess.run(hypothesis, feed_dict={X: [[4, 4]]}))
2. 케라스(Keras)를 활용한 선형회귀 분석
· keras는 tensorflow.keras 클래스를 가져와서 사용하고자 하는 모델을 import한다.
(*Sequential : 모델 정의 , Dense : 가설을 구현)
# Keras 사용
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD· keras는 numpy array로 데이터를 입력받는다.
x_data = np.array([[1], [2], [3]])
y_data = np.array([[10], [20], [30]])· 모델은 sequential로 정의한다. (Sequential은 순차적으로 레이어를 쌓아올린다.) 현재 선형회귀에서는 layer(출력)이 하나이기 때문에 Dense(1)로 입력한다.
model = Sequential([
Dense(1)
])· 모델 컴파일 구성을 할 경우 loss function은 MSE, optimizer는 SGD(Stochastic Gradient Descent),
lr(learning rate)는 0.1을 입력한다.
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.1))· 모델 학습은 fit이라는 함수를 사용한다. (x 데이터, y 데이터, 반복횟수(epochs))
model.fit(x_data, y_data, epochs=100) # epochs 복수형으로 쓰기!
반복 후 100번째 최종 loss가 0.0166임을 확인할 수 있다.
· 예측값을 확인하고 싶을 경우 아래와 같이 predict를 사용한다.
y_pred = model.predict([[4]])
print(y_pred)
'DataScience > 머신러닝' 카테고리의 다른 글
| 머신러닝 :: 머신러닝 모델(SVM, KNN, 의사결정 나무, 랜덤 포레스트) (0) | 2022.10.12 |
|---|---|
| 머신러닝 :: 논리 회귀(Logistic Regression) 개념 (0) | 2022.10.11 |
| 머신러닝 :: 캐글(kaggle) 데이터셋을 활용한 선형회귀 실습(2) (0) | 2022.10.11 |
| 머신러닝 :: 캐글(kaggle) 데이터셋을 활용한 선형회귀 실습 (1) | 2022.10.11 |
| Web 개발 :: 파이썬 django 인스타그램 클론 코딩 완료, 머신러닝_TIL#27 (0) | 2022.10.10 |




댓글