■ JITHub 개발일지 27일차

□ TIL(Today I Learned) ::
Django 인스타그램 클론 코딩, 머신러닝 선형회귀, 경사하강법, 데이터셋 분할 등
1. 머신러닝 기초 이론
- 알고리즘이란?
: 수학과 컴퓨터 과학, 언어학 또는 관련 분야에서 어떠한 문제를 해결하기 위해 정해진 일련의 절차나 방법을 공식화한 형태로 표현한 것, 계산을 실행하기 위한 단계적 절차 - 위키피디아
- 회귀와 분류
1) 회귀(Regression) : 입력값에 따른 출력값을 연속적인 실수값으로 예측
2) 분류(Classification) : 입력값이 따른 출력값을 계층으로 분류하여 결과값을 정리하는 방식. 이진분류(Binary classification)와 다중분류(Multi-class classification)가 있다.
※ 경우에 따라 회귀와 분류 둘 다 가능한 문제도 존재한다.
- 지도 학습, 비지도 학습, 강화 학습
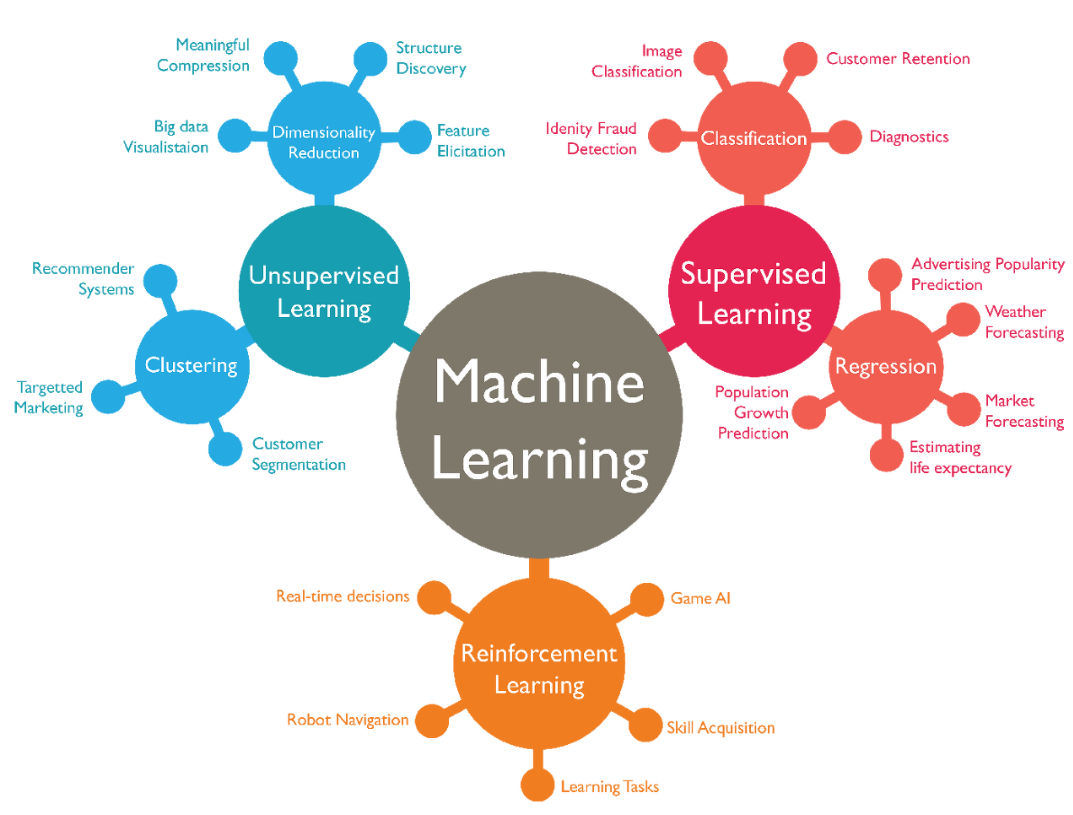
1) 지도학습(Supervised learning) : 학습 모델에 Input Data에 대한 정답(Annotations 또는 labeling)을 알려주면서 학습시키는 방법을 말한다.
2) 비지도학습(Unsupervised learing) : 학습 모델에 정답을 알려주지 않고 군집화(Clustering)하는 방법을 말한다.
※ 비지도학습의 종류
- 군집 (Clustering)
- K-평균 (K-Means)
- 계측 군집 분석(HCA, Hierarchical Cluster Analysis)
- 기댓값 최대화 (Expectation Maximization)
- 시각화(Visualization)와 차원 축소(Dimensionality Reduction)
- 주성분 분석(PCA, Principal Component Analysis)
- 커널 PCA(Kernel PCA)
- 지역적 선형 임베딩(LLE, Locally-Linear Embedding)
- t-SNE(t-distributed Stochastic Neighbor Embedding)
- 연관 규칙 학습(Association Rule Learning)
- 어프라이어리(Apriori)
- 이클렛(Eclat)
3) 강화 학습(Reinforcement learing) : 데이터가 주어지지 않거나, 데이터가 있어도 정답이 정해져있지 않으며, 실행과 오류를 반복하면서 보상(Reward)에 따라 학습하는 방법 (ex. 알파고)
- 강화학습의 개념
- 에이전트(Agent)
- 환경(Environment)
- 상태(State)
- 행동(Action)
- 보상(Reward)
에이전트(Agent)가 사전에 정의된 환경(Environment)에서 행동(Action) 목록에 따라 행동하면서 현재 상태(State)에서 높은 점수(Reward)를 얻는 방법을 찾아가며 행동(Action)하는 것이다.
- 선형회귀(Linear Regression) :
선형회귀는 추정하려는 대상이 선형임을 가정하여 예측식을 찾는다.
예를들어 아래와 같은 경우 1차함수의 직선으로 선형 모델을 표현할 수 있다. 그리고 이를 가설(Hypothesis)이라고 한다.
| 먹은 끼니의 수(끼) | 1 | 2 | 3 | 4 | 5 |
| 나의 몸무게(kg) | 60 | 62 | 64 | 66 | 68 |
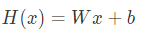
정확한 예측모델을 만들기 위해서 MSE(Mean Squared Error)를 활용한다. 그리고 이 Cost를 손실함수(Cost or Loss Function)이라고 한다.
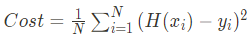
- 다중 선형회귀(Multi-variable Linear Regression) :
아래와 같이 입력값이 2개 이상되는 문제일 경우 다중 선형 회귀를 사용한다.

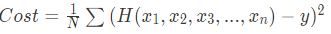
- 경사 하강법(Gradient descent method) :

입력값을 스텝(Learning rate)에 따라 점진적으로 이동하면서 그래프의 최소점에 도달했을 때(손실함수를 최소화 했을 때) 학습을 종료하는 학습방법
*Learning rate를 잘못 설정할 경우, Local cost minimum에 빠지거나 overshooting할 수 있기 때문에 learning rate를 잘 선정하는 것이 중요하다. 목표는 Global cost minimum을 찾는 것이다.

- 학습/검증/테스트 데이터
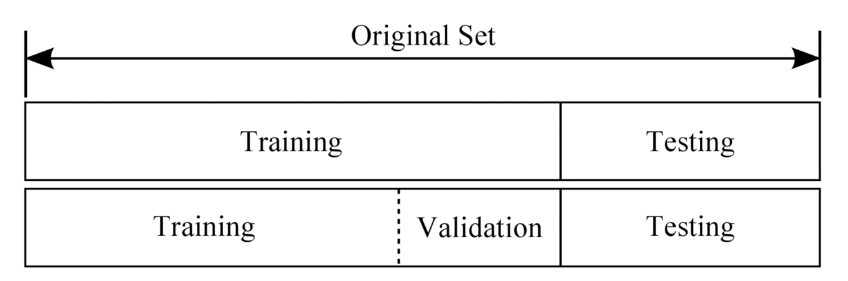
1) Training set : 머신러닝 모델을 학습시키는 용도로 사용되며, 전체 데이터셋의 80% 차지
2) Validation set : 머신러닝 모델의 성능을 검증하고 튜닝하는 지표, 모델에게 직접 데이터셋을 보여주지 않으므로 모델의 성능에 영향을 미치지는 않으며, 손실함수, Optimizer등을 바꾸면서 성능을 검증한다.
3) Test set : 정답 라벨이 없는 실제 환경에서의 평가 데이터 셋
- 간단한 선형회귀 실습
· 텐서플로우 Import, 데이터와 변수 설정
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
x_data = [[1, 1], [2, 2], [3, 3]]
y_data = [[10], [20], [30]]
X = tf.compat.v1.placeholder(tf.float32, shape=[None, 2])
Y = tf.compat.v1.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random.normal(shape=(2, 1)), name='W')
b = tf.Variable(tf.random.normal(shape=(1,)), name='b')· 가설과 비용함수, Optimizer 정의
hypothesis = tf.matmul(X, W) + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
optimizer = tf.compat.v1.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)· 스텝별 결과 출력하며 비용함수 확인
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
for step in range(50):
c, W_, b_, _ = sess.run([cost, W, b, optimizer], feed_dict={X: x_data, Y: y_data})
print('Step: %2d\t loss: %.2f\t' % (step, c))
print(sess.run(hypothesis, feed_dict={X: [[4, 4]]}))
· 케라스 사용할 경우 아래와 같이 실험할 수 있다.
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
x_data = np.array([[1], [2], [3]])
y_data = np.array([[10], [20], [30]])
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.1))
model.fit(x_data, y_data, epochs=100) # epochs 복수형으로 쓰기!y_pred = model.predict([[4]])
print(y_pred)
□ TIF(Today I Felt) ::
Django 인스타그램 클론 코딩 KPT 분석
- - Keep :
1) 프로젝트에 대한 열정
2) 서로 존중하는 자세와 말투
3) 모르는 것은 질문하고 같이 해결하는 자세
- Problem
문제점1) 프로젝트를 진행하면서 깃허브 관리가 잘 되지 않았던 점
해결 방안1) 팀 내에서 깃 커밋 Rule을 정하고, 어렵더라도 Git을 사용해보도록 한다.
문제점2) 개념 이해가 부족한 상황에서 프로젝트에 투입되어 이해하지 못하는 코드가 남아있던 점
해결 방안2) 현 프로젝트 결과는 코드리뷰를 통해 보완하고, 이후 프로젝트에서는 자신이 이해하고, 타인에게 설명해 줄 수 있는 코드들을 위주로 개발한다.
문제점3) 또, 프로젝트를 진행하며 잠을 줄여가며 하다보니 집중력이 저하되어 효율이 떨어짐을 경험했다.
해결 방안3) 납기를 정하여 제한된 시간내에서 효율적으로 작업을 진행하는 것이 필요하다.
- Try :
노력 1) 기초개념을 프로젝트에 도입되기 전에 탄탄히 해야겠다. 만약 이해가지 않는 부분이 있으면 꼭 해결하고 넘어가도록 한다.
노력 2) 내가 짠 코드는 팀원들에게 꼭 설명해줄 수 있어야 한다. '나' 자신만 알고 넘어가는 코드가 아니라 토의해보고 모르는 부분이나, 더 좋은 코드는 없는지 생각해본다.
- Feel :
처음엔 프로젝트를 가볍게 생각했지만, 고민도 정말 많이하고, 시간도 많이 썼던 경험이다. 부족한 실력으로 우여곡절도 많이 겪었고, 프로젝트가 끝나고 나서도 아직도 코드에 대한 이해도나 부족함이 남아있는 것이 아쉽지만, 어려웠던 만큼 재미도 비례했다. 다음 프로젝트에서는 좀 더 팀원들과 소통이 원활히 되었으면 좋겠다.
'DataScience > 머신러닝' 카테고리의 다른 글
| 머신러닝 :: 머신러닝 모델(SVM, KNN, 의사결정 나무, 랜덤 포레스트) (0) | 2022.10.12 |
|---|---|
| 머신러닝 :: 논리 회귀(Logistic Regression) 개념 (0) | 2022.10.11 |
| 머신러닝 :: 캐글(kaggle) 데이터셋을 활용한 선형회귀 실습(2) (0) | 2022.10.11 |
| 머신러닝 :: 캐글(kaggle) 데이터셋을 활용한 선형회귀 실습 (1) | 2022.10.11 |
| 머신러닝 :: 선형회귀(Linear Regression) 분석 실습(Tensorflow, Keras) (0) | 2022.10.11 |




댓글