
머신러닝 논리 회귀(Logistic Regression)
1. 논리 회귀(Logistic Regression)
1) Logistic Function(=Sigmoid Function)
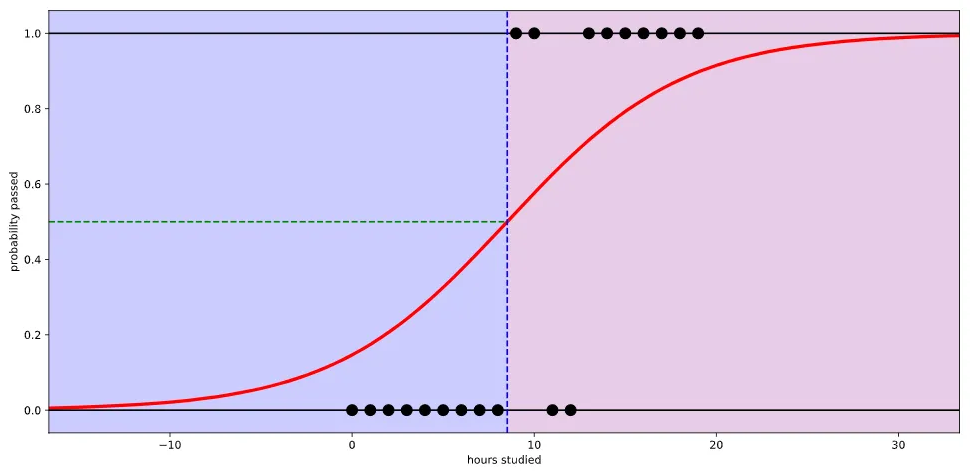
· 로지스틱 함수는 어떤 입력값(x)에도 출력결과(y)가 항상 0에서 1사이의 값이 된다.
다시 말하면, x값이 음수방향으로 갈수록 출력값이 0에 수렴하고, 양수방향으로 커질 수록 출력값이 1에 수렴하는 함수이다.

아래 그림의 경우 초록색 선을 임계치(Threshold)로 사용하여 0.5를 통과하면 Pass, 통과하지 않으면 Fail 등과 같이 판단기준으로 사용할 수 있다. 경우에 따라서 임계치는 높이거나 낮추도록 조정할 수 있다.
2) 논리회귀에서의 식
· 시그모이드 함수에 선형회귀식을 대입하여 사용한다.

· 이 때 손실함수는 아래와 같이 표현할 수 있다.
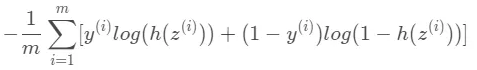
· 위의 식보다 손실함수를 예측하는 것이 중요하다.
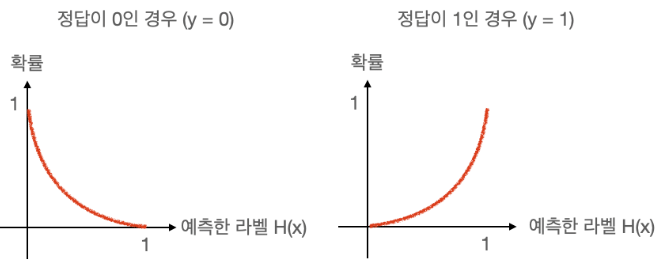
· CrossEntropy함수는 다른 사건의 확률을 곱해서 Entropy를 계산한 것으로, 신경망의 손실함수로 활용되며, 머신러닝의 분류 모델의 수행능력을 측정하는 지표가 된다.
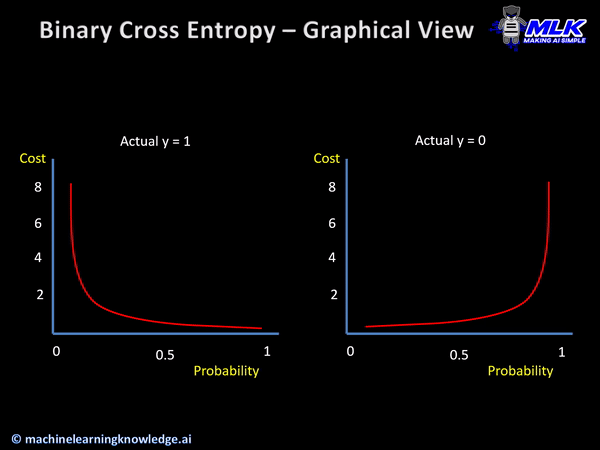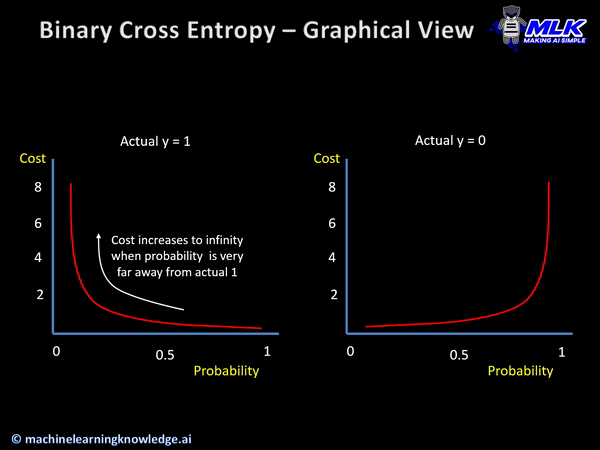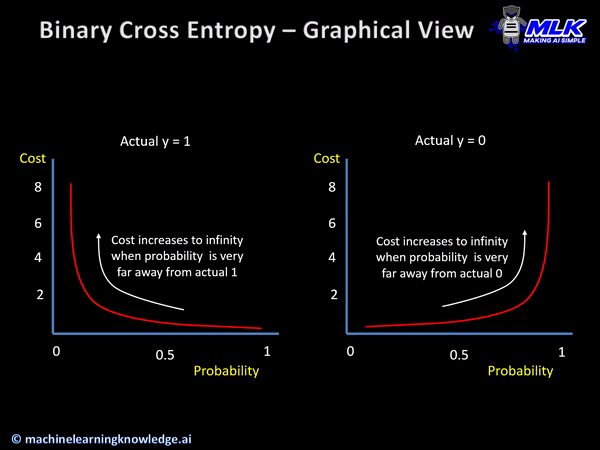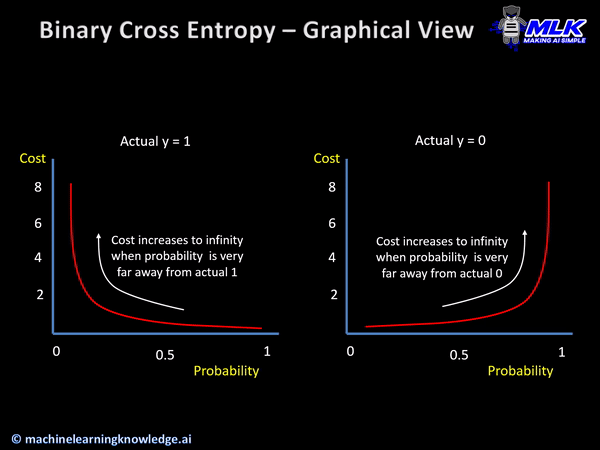
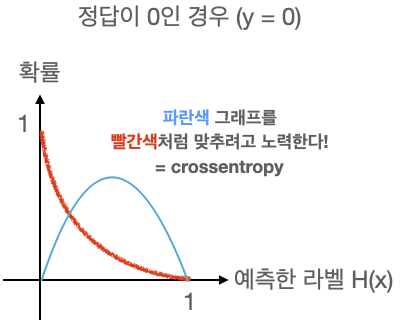
· Logistic regression에서는 손실함수를 최소화하는 방향으로 학습하여 확률분포그래프를 그리며, 이때의 손실함수가 Cross Entropy가 된다.
· Keras에서 이진 논리 회귀의 경우 binary_crossentropy 손실함수를 사용한다.
2. 다항 논리 회귀(Multinomial Logistic Regression)
1) 원 핫 인코딩(One-hot encoding)
다항 분류(Multi-label classification) 문제를 풀 때 출력값의 형태를 표현하는 방법 중 하나.
※ 원 핫 인코딩 예시
| 성적 | 클래스(Class) | One-hot encoded |
| A | 0 | [1, 0, 0, 0, 0] |
| B | 1 | [0, 1, 0, 0, 0] |
| C | 2 | [0, 0, 1, 0, 0] |
| D | 3 | [0, 0, 0, 1, 0] |
| E | 4 | [0, 0, 0, 0, 1] |
- 원 핫 인코딩을 만드는 방법
- 클래스(라벨)의 개수만큼 배열을 0으로 채운다.
- 각 클래스의 인덱스 위치를 정한다.
- 각 클래스에 해당하는 인덱스에 1을 넣는다.
2) Softmax 함수와 손실함수
· 다항 논리회귀에서는 여러개의 항이 있기 때문에 0과 1로만 결과를 표현하기 어렵다.
Softmax는 선형 모델에서 나온 결과(Logit)를 모두가 더하면 1이 되도록 만들어주는 함수이다.


· 위의 그림에서 보면 알 수 있듯이, Logit에서 비슷한 가중치를 만들어주고
전체 합이 1이 되도록 만들어주는 함수가 softmax함수이다.
그리고 이 결과를 정답값과 비교하여 차이를 줄여주는 함수가 Cross Entropy가 된다.
(*Keras에서는 다항논리 회귀의 경우 categorical_crossentropy 손실함수를 사용한다.)
'DataScience > 머신러닝' 카테고리의 다른 글
| 머신러닝 :: 전처리(Preprocessing)의 개념 및 종류 (0) | 2022.10.12 |
|---|---|
| 머신러닝 :: 머신러닝 모델(SVM, KNN, 의사결정 나무, 랜덤 포레스트) (0) | 2022.10.12 |
| 머신러닝 :: 캐글(kaggle) 데이터셋을 활용한 선형회귀 실습(2) (0) | 2022.10.11 |
| 머신러닝 :: 캐글(kaggle) 데이터셋을 활용한 선형회귀 실습 (1) | 2022.10.11 |
| 머신러닝 :: 선형회귀(Linear Regression) 분석 실습(Tensorflow, Keras) (0) | 2022.10.11 |




댓글