
머신러닝 전처리(Preprocessing)의 개념 및 종류
1. 전처리(Preprocessing)
· 넓은 범위의 데이터 정제작업을 뜻한다. 필요없는 데이터를 지우고 필요한 데이터만 남기거나, 비어있는 값(null)이 있는 행을 삭제하는 것, 정규화(Normalization), 표준화(Standardization)등의 많은 작업을 포함하고 있다.
1) 정규화(Normalization)
: 데이터가 0과 1사이의 범위 내에 속하도록 만든다. 같은 특성의 대이터 중 가장 작은 값을 0으로, 가장 큰 값을 1으로 지정하고 이 기준에 따라 나머지 데이터들을 변환한다.

2) 표준화(Standardization)
: 표준화는 데이터 분포를 정규분포로 변환해준다. 즉 데이터의 평균을 0으로 잡고, 표준편차가 1이 되도록 한다.
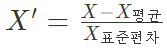
일단 데이터의 평균을 0으로 잡으면 데이터 중심이 0에 맞춰지게 된다.(Zero-centered) 그리고 표준편차를 1로 만들어주면 데이터가 정규화(Normalized)된다. 이렇게 되면 일반적으로 학습속도(최저점 수렴 속도)가 빠르고 Local minima에 빠질 가능성이 적다.
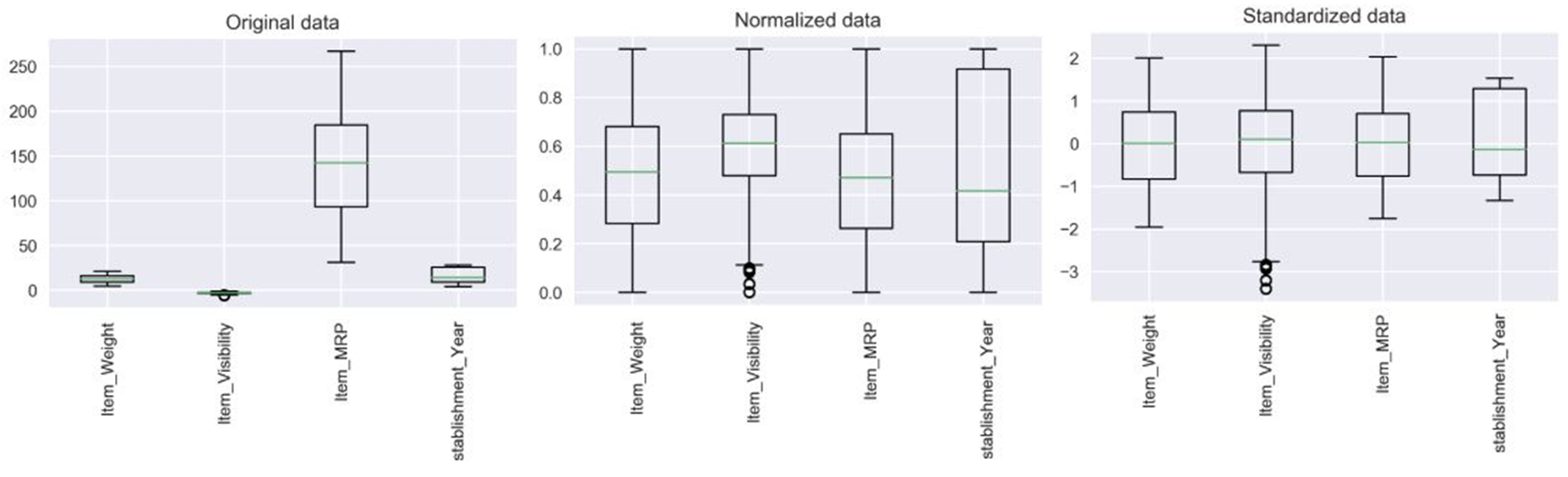
아래 그림들을 보면 정규화와 표준화를 구분하는데 도움이 된다.

반응형
'DataScience > 머신러닝' 카테고리의 다른 글
| 머신러닝 :: 다항 논리회귀(Logistic Regression)_와인 종류 예측 (0) | 2022.10.12 |
|---|---|
| 머신러닝 :: 이진 논리회귀(Logistic Regression)_캐글(Kaggle) 타이타닉 생존자 예측 (0) | 2022.10.12 |
| 머신러닝 :: 머신러닝 모델(SVM, KNN, 의사결정 나무, 랜덤 포레스트) (0) | 2022.10.12 |
| 머신러닝 :: 논리 회귀(Logistic Regression) 개념 (0) | 2022.10.11 |
| 머신러닝 :: 캐글(kaggle) 데이터셋을 활용한 선형회귀 실습(2) (0) | 2022.10.11 |




댓글