
머신러닝 모델(SVM, KNN, 의사결정나무, 랜덤 포레스트)
1. SVM(Support Vector Machine)
· 아래 그림의 오른쪽 그래프처럼 각 서포트 벡터를 구분할 수 있는 축을 그리고 margin을 계산한다.
SVM에서는 margin이 최대가 되도록 모델을 학습시킨다.
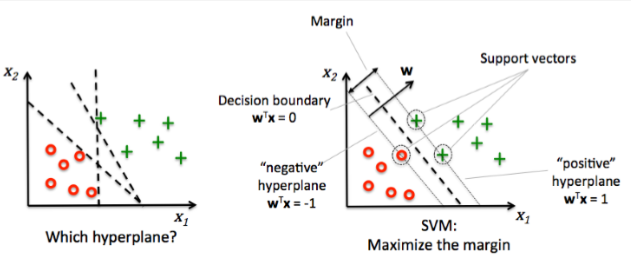
· 위의 그림에서는 x1, x2 두가지의 특징으로 구분했을 경우이지만, 두개의 특징으로도 구분이 되지않는 경우가 생길 수 있다. 이 때에는 x3, x4, ...의 특징을 추가하여 feature(특성)를 3차원 이상으로 만들어줄 수 있다. Feature가 늘어날 수록 classifier의 성능은 높아진다.
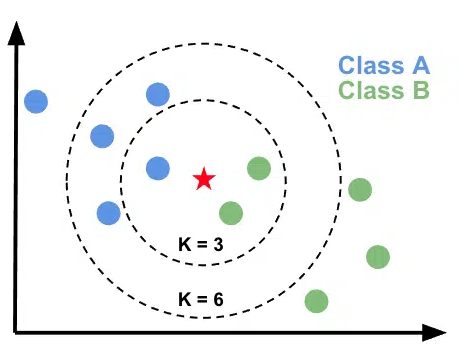
2. KNN(k-Nearest Neighbors)
· 가까운 거리 내의 개체를 보고 비슷한 특성을 가진 개체끼리 군집화하는 알고리즘
3. 의사결정나무(Decision Tree)
· 각 조건을 지나면서 Yes/No를 판별하고, 결과에 따라 추론하는 알고리즘을 말한다.

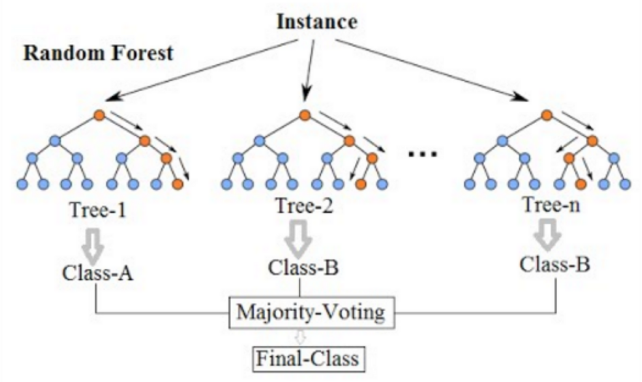
4. 랜덤 포레스트(Random Forest)
· 위에서 본 의사결정나무를 여러개 합친 모델을 말한다. 여러 의사결정나무들이 결정하고 마지막에 최종 투표(Majority-Voting)를 통해 결론을 낸다.
반응형
'DataScience > 머신러닝' 카테고리의 다른 글
| 머신러닝 :: 이진 논리회귀(Logistic Regression)_캐글(Kaggle) 타이타닉 생존자 예측 (0) | 2022.10.12 |
|---|---|
| 머신러닝 :: 전처리(Preprocessing)의 개념 및 종류 (0) | 2022.10.12 |
| 머신러닝 :: 논리 회귀(Logistic Regression) 개념 (0) | 2022.10.11 |
| 머신러닝 :: 캐글(kaggle) 데이터셋을 활용한 선형회귀 실습(2) (0) | 2022.10.11 |
| 머신러닝 :: 캐글(kaggle) 데이터셋을 활용한 선형회귀 실습 (1) | 2022.10.11 |




댓글