
머신러닝 이진 논리회귀_캐글(Kaggle) 와인 종류 예측
1. 이진 논리회귀(Binary Logistic Regression)
※ 와인 종류 예측하기
1) 데이터 다운로드
· 캐글(Kagge) 사용자 API 정보 입력
import os
os.environ['KAGGLE_USERNAME'] = 'kairess' # username
os.environ['KAGGLE_KEY'] = '7d0443b2dfffc57c94271fd797511896' # key· 데이터 다운로드
!kaggle datasets download -d brynja/wineuci
!unzip wineuci.zip
2) 필요한 패키지 임포트
· 다항 논리회귀에서는 One-Hot encoding을 해야 하기 때문에 사이킷런을 통해 OneHotEncoder를 임포트 한다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
3) 데이터 로드
· 데이터를 보면 헤더에 값이 들어가있는 것을 확인할 수 있다.
df = pd.read_csv('Wine.csv')
df.head(5)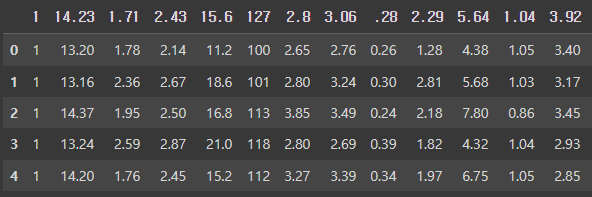
· 헤더의 name을 아래와 같이 지정해준다.
df = pd.read_csv('Wine.csv', names=[
'name'
,'alcohol'
,'malicAcid'
,'ash'
,'ashalcalinity'
,'magnesium'
,'totalPhenols'
,'flavanoids'
,'nonFlavanoidPhenols'
,'proanthocyanins'
,'colorIntensity'
,'hue'
,'od280_od315'
,'proline'
])
df.head(5)
· 정답 라벨의 개수 확인 (countplot)
sns.countplot(x=df['name'])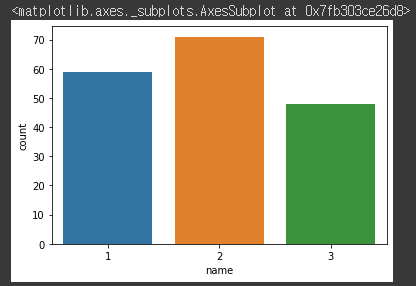
4) 데이터 전처리
· 비어있는 행 확인 : 비어있는 행이 없음을 확인할 수 있었다.
print(df.isnull().sum())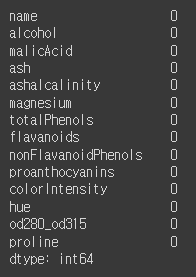
· x, y 데이터 분할 : name칼럼을 제외하곤 모두 x_data로 넣는다.
x_data = df.drop(columns=['name'], axis=1)
x_data = x_data.astype(np.float32)
x_data.head(5)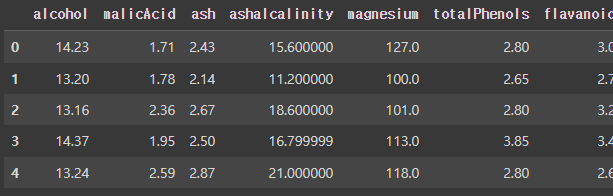
· name칼럼은 y_data로 넣는다.
y_data = df[['name']]
y_data = y_data.astype(np.float32)
y_data.head(5)
· 데이터 표준화 - StandardScaler를 사용
scaler = StandardScaler()
x_data_scaled = scaler.fit_transform(x_data)
print(x_data.values[0])
print(x_data_scaled[0])
· One-hot encoding : One-hot encoder를 통해 [1.] 을 [1. 0. 0.]으로 변경해주었다,
encoder = OneHotEncoder()
y_data_encoded = encoder.fit_transform(y_data).toarray()
print(y_data.values[0])
print(y_data_encoded[0])
"""
[1.]
[1. 0. 0.]
"""
· 학습/검증 데이터 분할 : 여기서 x_data는 scaled된 값으로, y_data는 encoded된 값으로 넣어주어야 한다.
트레이닝 셋 - 80%, 테스트 셋 - 20%로 변경한다.
x_train, x_val, y_train, y_val = train_test_split(x_data_scaled, y_data_encoded, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)
"""
(142, 13) (36, 13)
(142, 3) (36, 3)
"""
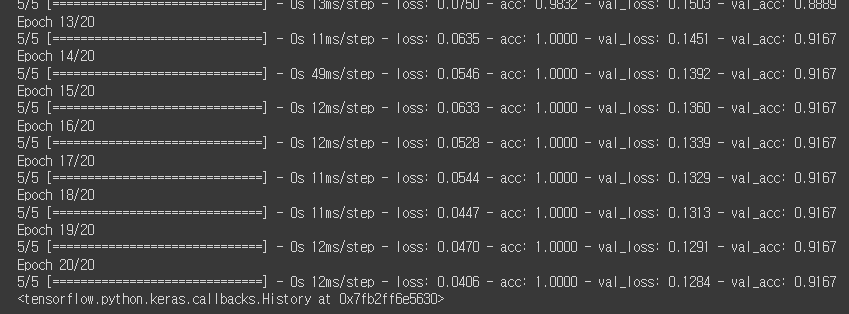
· 모델 학습
model = Sequential([
Dense(3, activation='softmax')
])
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.02), metrics=['acc'])
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기!
)
반응형
'DataScience > 머신러닝' 카테고리의 다른 글
| 머신러닝 :: 딥러닝 XOR 예측 실습(이진 논리회귀, MLP, keras functional API) (0) | 2022.10.13 |
|---|---|
| 머신러닝 :: 딥러닝 주요 개념(배치, 활성화 함수, 과적합, 앙상블) (0) | 2022.10.13 |
| 머신러닝 :: 이진 논리회귀(Logistic Regression)_캐글(Kaggle) 타이타닉 생존자 예측 (0) | 2022.10.12 |
| 머신러닝 :: 전처리(Preprocessing)의 개념 및 종류 (0) | 2022.10.12 |
| 머신러닝 :: 머신러닝 모델(SVM, KNN, 의사결정 나무, 랜덤 포레스트) (0) | 2022.10.12 |




댓글