
딥러닝 개념(배치, 활성화 함수, 과적합, 앙상블)
1. 딥러닝의 개념
· 자연계에는 직선으로 설명할 수 없는 문제들이 훨씬 많다. 이러한 문제들은 선형회귀를 반복한다고 해결이 되지 않기 때문에 선형회귀에 비선형 계산식을 추가하여 문제를 해결할 수 있다.

· 위와 같이 선형 회귀 사이에 비선형 들어간 여러개의 층(layer)으로 구성된 것을 딥러닝(Deep learning)이라고 한다.
딥러닝(Deep learning)은 Deep neural networks, Multilayer Perceptron(MLP)라고도 표현한다.
2. 딥러닝, Deep neural networks의 구성
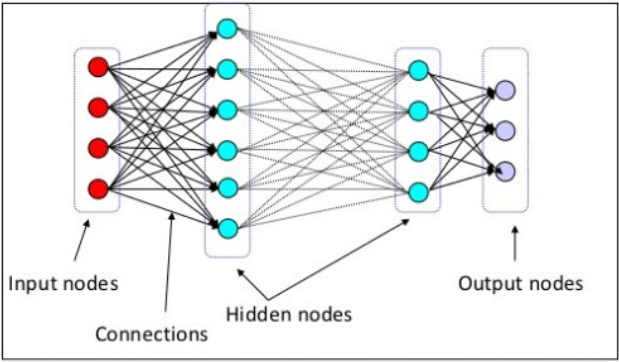
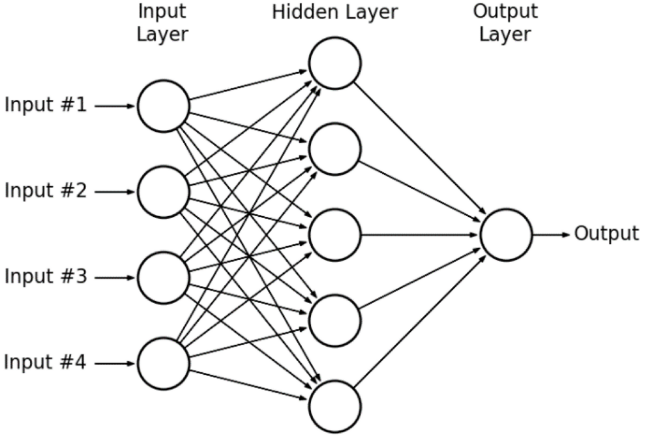
· MLP는 아래 3개의 층으로 구분할 수 있다.
- Input layer(입력층): 네트워크의 입력. 학습시키고자 하는 값, x value.
- Output layer(출력층): 네트워크의 출력. 예측한 값, y value
- Hidden layers(은닉층): 입력층과 출력층을 제외한 중간층,
완전연결 계층(Fully connected layer = Dense layer)으로 이루어져 있다.
· 노드의 갯수는 보통 은닉층의 중간부분을 넓게 만드는 경우가 많다.
ex)
- 입력층의 노드 개수 4개
- 첫 번째 은닉층 노드 개수 8개
- 두 번째 은닉층 노드 개수 16개
- 세 번째 은닉층 노드개수 8개
- 출력층 노드개수 3개
· 활성화함수는 은닉층의 바로 뒤에 위치시킨다.

· 모델의 성능을 테스트하기 위해서는 은닉층의 너비(width)와 깊이(depth)를 조절해가며 테스트할 수 있다.
이 작업은 시간이 많이 걸리는 작업이지만, 과적합과 과소적합을 방지하기 위해 꼭 필요한 중요한 작업이다.
1) 네트워크의 너비를 늘리는 방법

2) 네트워크의 깊이를 늘리는 방법

3) 네트워크의 너비와 깊이를 모두 늘리는 방법

3. 딥러닝의 주요 개념
1) 모델을 학습시키는 데 쓰이는 단위, Batch size, Epoch (배치 사이즈, 에폭)
· Batch와 Iteration
: 예를 들어서 1,000만개의 데이터셋을 1,000개 씩으로 쪼개어 10,000번을 반복한다고 할 경우,
Batch : 데이터셋을 쪼개는 단위
Iteration : 반복하는 과정
· Epoch
: 머신러닝에서는 똑같은 데이터셋을 가지고 반복학습을 하는데, 전체 데이터셋을 한 번 돌 때 한 epoch이 끝난다.
2) Activation functions (활성화 함수)
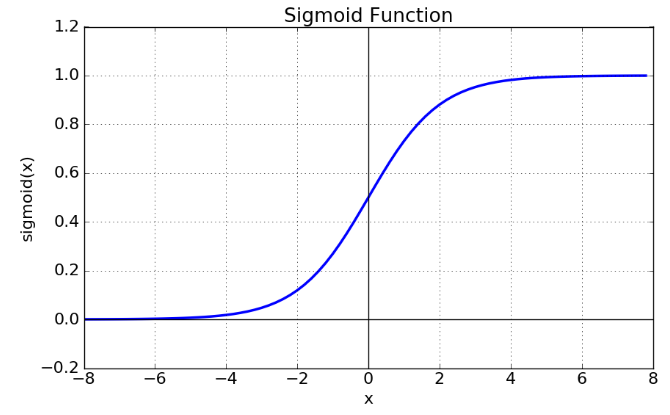
· 인체의 뉴런처럼 일정 임계치를 넘어서면 다음 함수가 실행되도록 하는 뉴런의 신호전달체계를 흉내내는 함수를 활성화 함수라고 지칭한다.
· 활성화 함수는 비선형 함수이며 대표적으로 시그모이드(Sigmoid) 함수가 있다.

· 시그모이드 함수를 좀 더 살펴보면 아래와 같다.
· 활성화 함수는 아래와 같이 여러 종류가 있다.
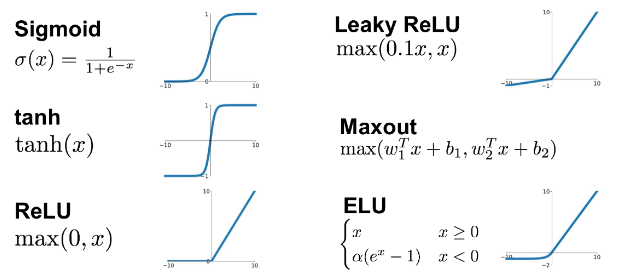
· 딥러닝에서 사용하는 활성화 함수 중 ReLU(렐루) 함수는 학습이 빠르고, 연산 비용이 적고, 구현이 간단하기 때문에 가장 보편적으로 사용하고 있다.
· 딥러닝 모델을 설계할 때 여러 활성화 함수를 교체하는 작업을 거치는데, 이 과정을 모델 튜닝이라고 한다.
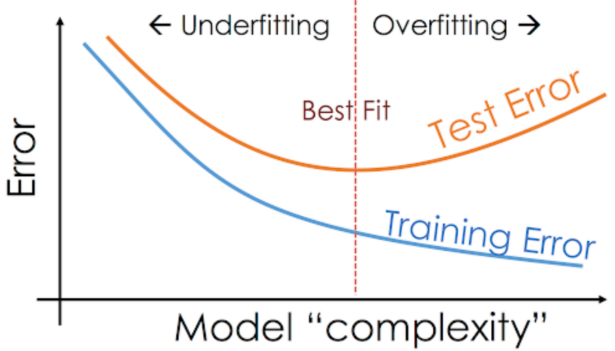
3) Overfitting, Underfitting (과적합, 과소적합)
· 딥러닝 모델을 설계/튜닝/학습 중에 간혹 Training loss는 낮아지는데, Validation loss가 높아지는 시점이 있다. 이러한 현상을 과적합이라고 지칭한다. 과적합은 문제의 난이도에 비해 모델의 복잡도(Complexity)가 클 경우 발생하는 현상이다.
이를 반대로 풀어야 하는 문제의 난이도에 비해 모델의 복잡도가 낮을 경우, 문제를 제대로 풀지 못하는 과소적합이 발생하기도 한다. 이 때문에 최적의 복잡도를 가진 모델을 찾아야 하고, 이를 위해 여러번의 튜닝과정을 거쳐 최적합(Best fit)의 모델을 찾아야 한다. (*과적합을 해결하는 방법으로는 데이터를 더 모으거나, Data augmenation, Dropout 등이 있다.)
4. 딥러닝의 주요 스킬
1) Data augmentation (데이터 증강기법)
· 과적합을 해결하기 위해서는 데이터의 갯수를 늘리는 것이 좋으나, 실무에서는 데이터가 부족한 경우가 많다. 이를 해결하기 위해 '데이터 증강기법'을 사용할 수 있다. 데이터 증강기법은 원본 이미지 한장을 여러가지 방법으로 복사/변환하여 동일한 객체로 결과를 출력하도록 학습시킨다.

2) Dropout (드랍아웃)
· 과적합을 해결하기 위한 다른 방법으로는 드랍아웃이 있다. 드랍아웃은 아래 그림처럼 각 노드들이 이어진 선을 랜덤하게 빼서 없애는 작업을 하는 것을 말한다.

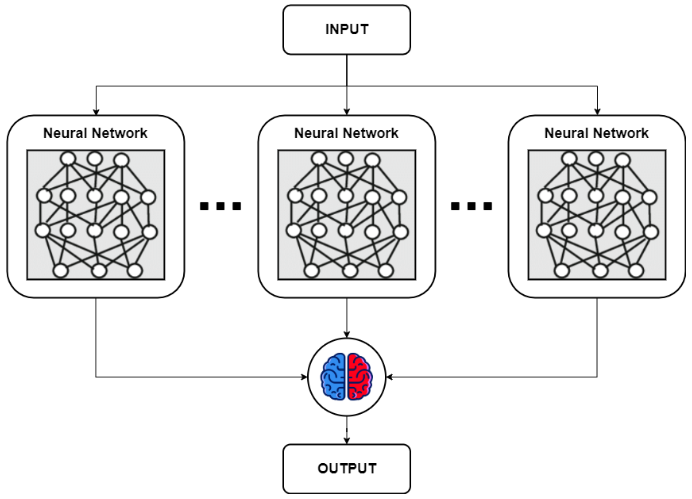
3) Ensemble (앙상블)
· 앙상블은 주어진 자료로부터 여러 예측모형들을 만든 후 이를 조합하여 하나의 최종 예측 모형을 만드는 것을 말한다.앙상블 기법에는 배깅(Bagging), 부스팅(Boosting), 랜덤 포레스트(Random Forest)가 있다.
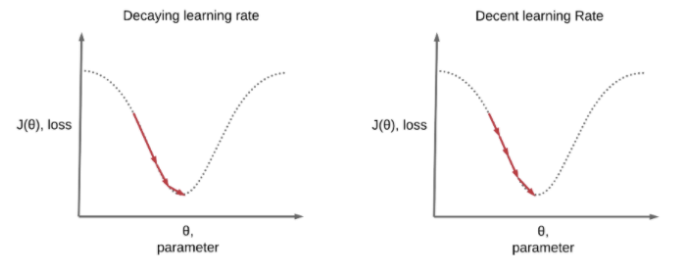
4) Learning rate decay (Learning rate schedules)
· Learning rate decay 기법은 Local minimum에 빠르게 도달하고 싶을 때 사용한다. 아래 사진을 보면, 왼쪽 그림은 학습의 앞부분은 큰 폭에서 뒷 부분으로 갈 수록 작은 폭으로 움직여 효율적으로 Local minimum을 찾는 모습이고, 오른쪽 그림은 learning rate의 폭을 고정시켰을 때의 모습이다.
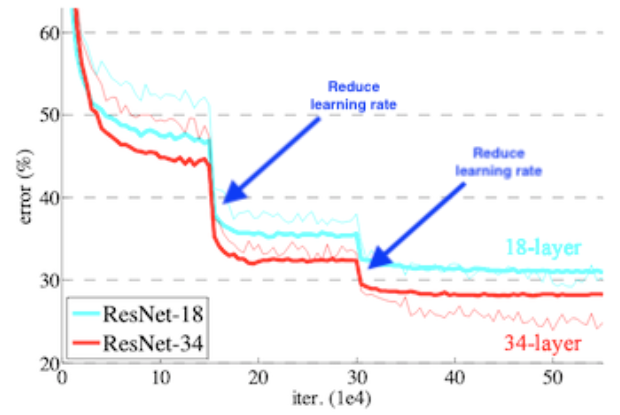
· Learning rate decay 기법을 사용하면 아래와 같이 learning rate가 줄어들 때마다 Error 값이 큰 폭으로 떨어지는 현상을 확인할 수 있다.
· Keras에서는 tf.keras.callbacks.LearningRateScheduler() 와 tf.keras.callbacks.ReduceLROnPlateau() 를 사용하여 학습중 Learning rate를 조절한다.
- 참고 1 : https://keras.io/api/callbacks/learning_rate_scheduler/
- 참고 2 : https://keras.io/api/callbacks/reduce_lr_on_plateau
'DataScience > 머신러닝' 카테고리의 다른 글
| 머신러닝 :: 딥러닝 MNIST 실습_캐글 Sign Language 데이터셋 (0) | 2022.10.13 |
|---|---|
| 머신러닝 :: 딥러닝 XOR 예측 실습(이진 논리회귀, MLP, keras functional API) (0) | 2022.10.13 |
| 머신러닝 :: 다항 논리회귀(Logistic Regression)_와인 종류 예측 (0) | 2022.10.12 |
| 머신러닝 :: 이진 논리회귀(Logistic Regression)_캐글(Kaggle) 타이타닉 생존자 예측 (0) | 2022.10.12 |
| 머신러닝 :: 전처리(Preprocessing)의 개념 및 종류 (0) | 2022.10.12 |




댓글