
딥러닝_합성곱 신경망(CNN)
1. 합성곱 신경망(CNN)
· 컴퓨터 비전(Computer Vision, CV) 분야에서 사용되는 이미지 처리 방식으로 입력데이터와 필터의 각각의 요소를 서로 곱한 후 모두 더하여 출력값을 생성한다.

※ 참고. 합성곱 관련 논문자료 中

· 합성곱 출력결과는 아래와 같이 순차적으로 생성된다.
· Filter, Strides and Padding
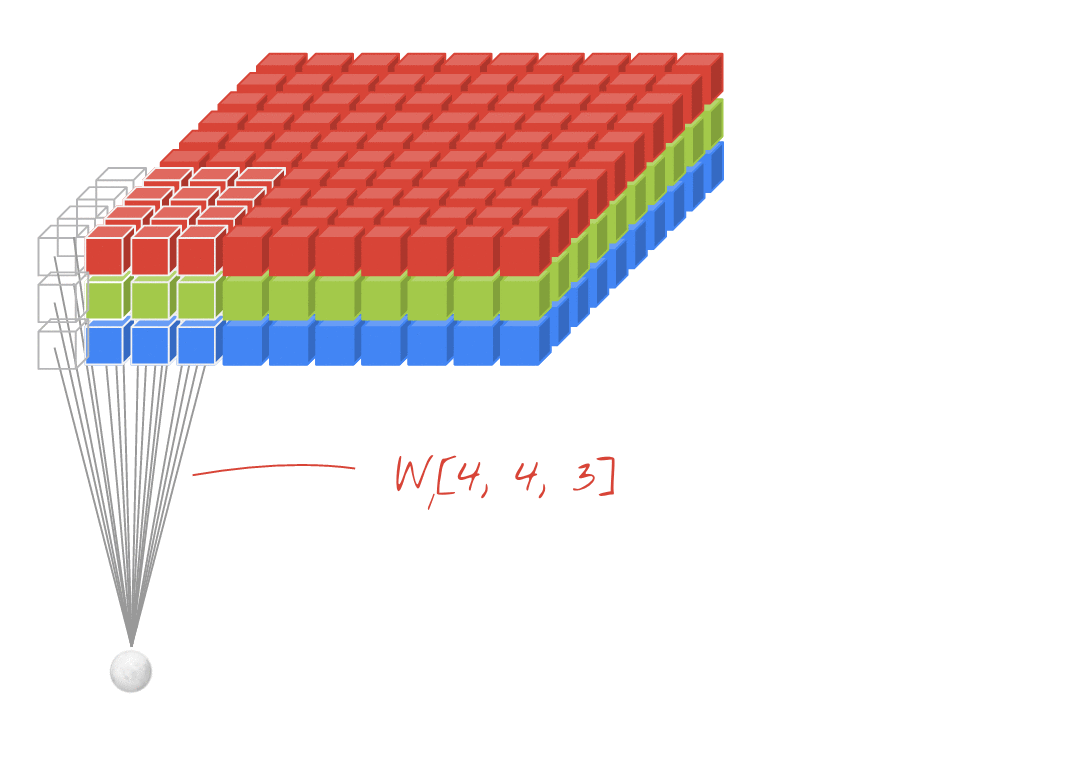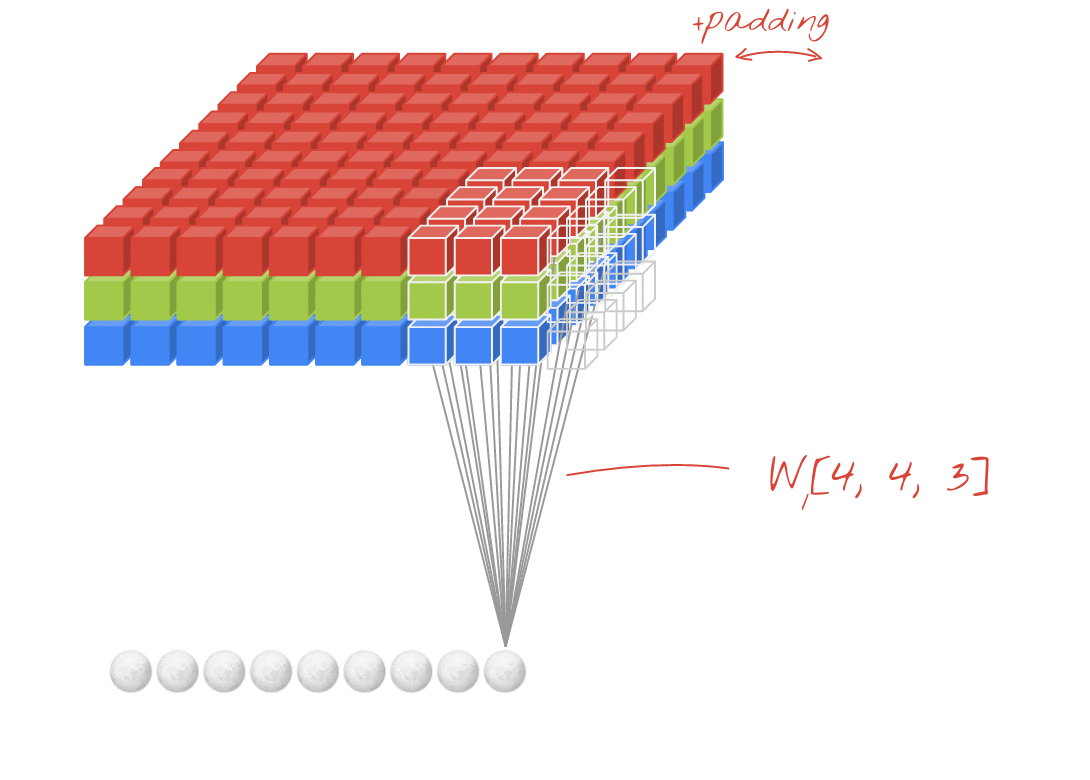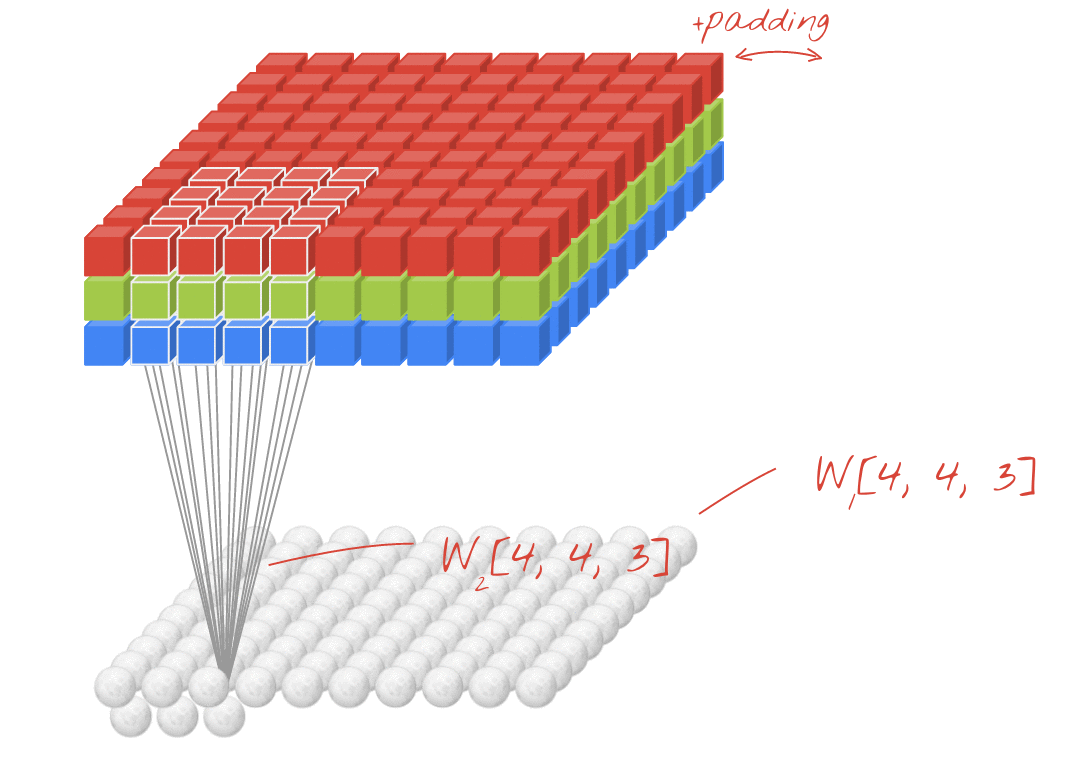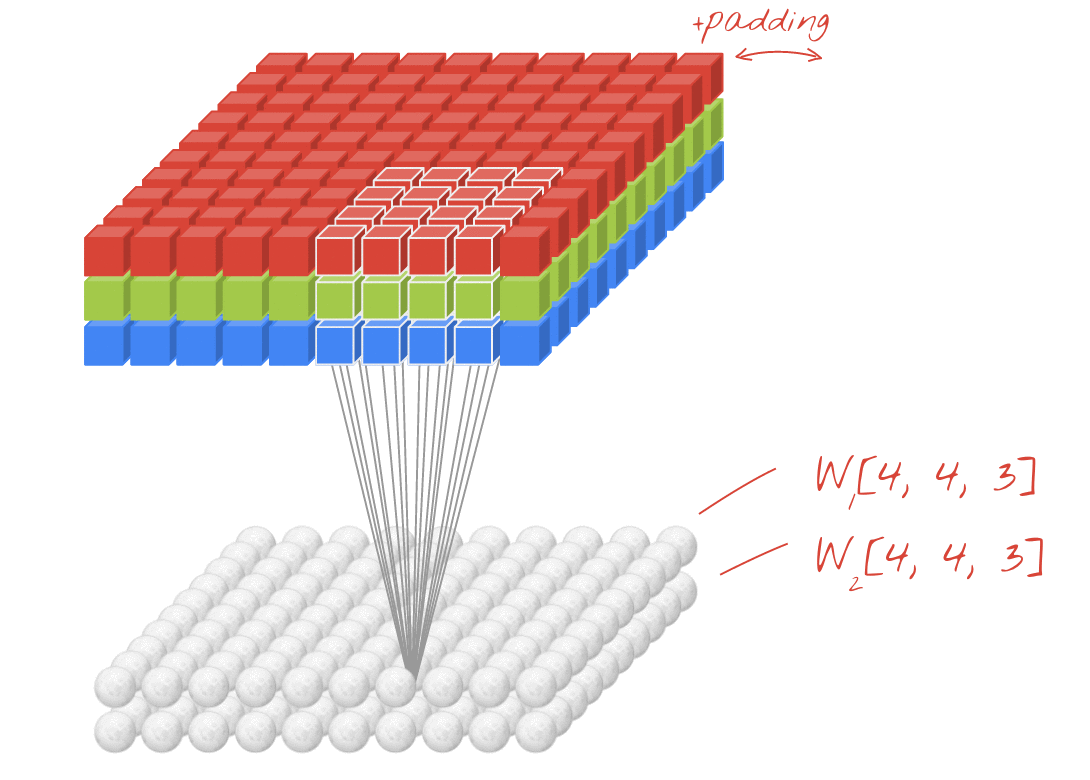
아래 왼쪽 그림에서 보면 5x5크기의 입력이 주어졌을 때 3x3크기의 필터(Filter 또는 Kernel)를 사용하여 합성곱을 계산하면 3x3크기의 특성맵(Feature map)을 생성할 수 있다. 이 때 필터가 이동하는 간격을 스트라이드(Stride)라고 부른다.
그런데 이러한 연산을 진행하면 연산 특성상 출력값인 맵의 크기가 줄어들게 되기 때문에 아래 우측 그림과 같이 패딩(Padding 또는 Margin)을 주어 스트라이드가 1일때 입력값과 특성 맵의 크기를 같게 만들 수 있다.
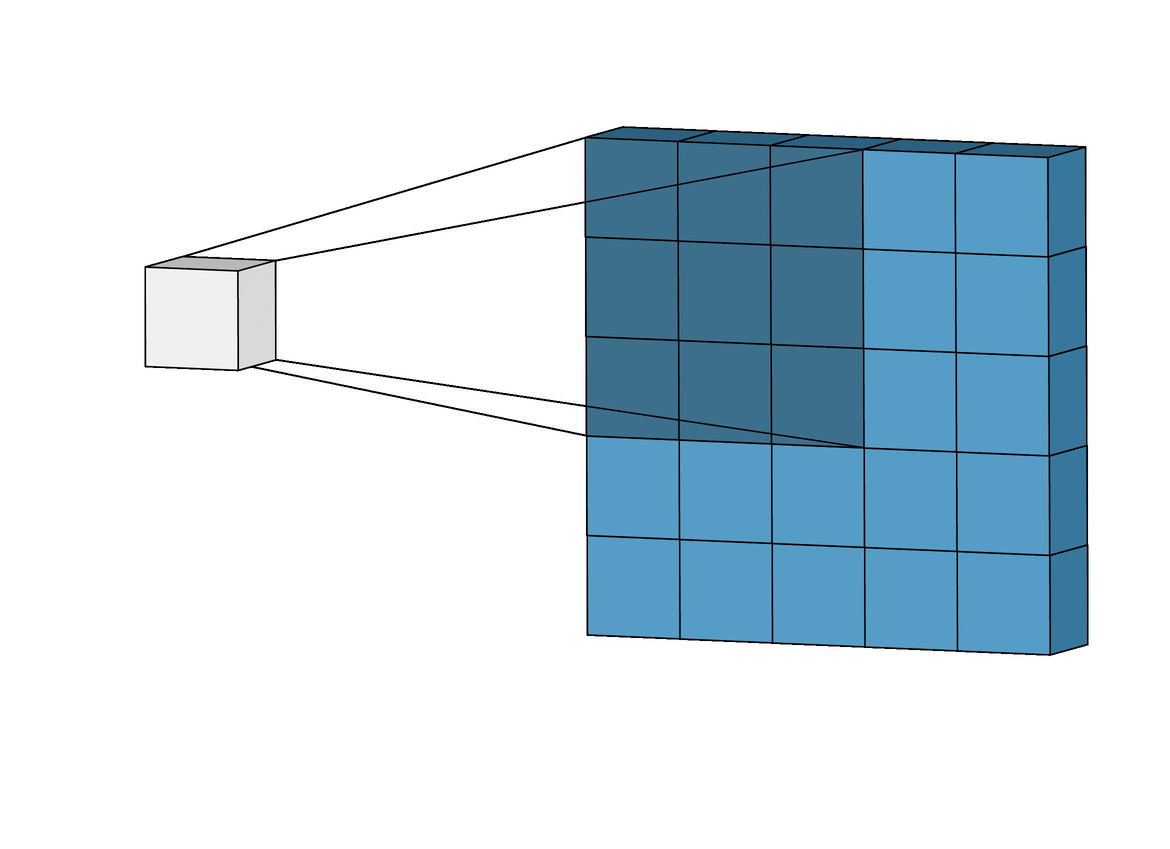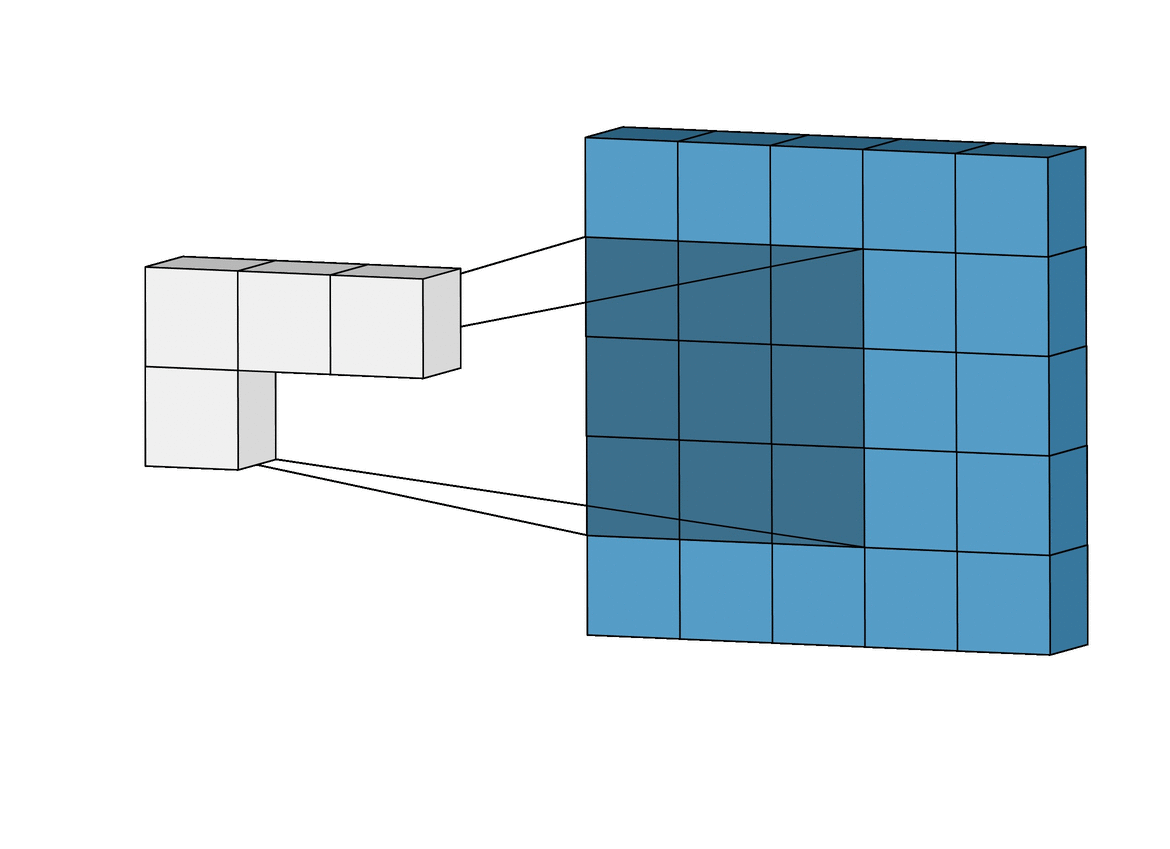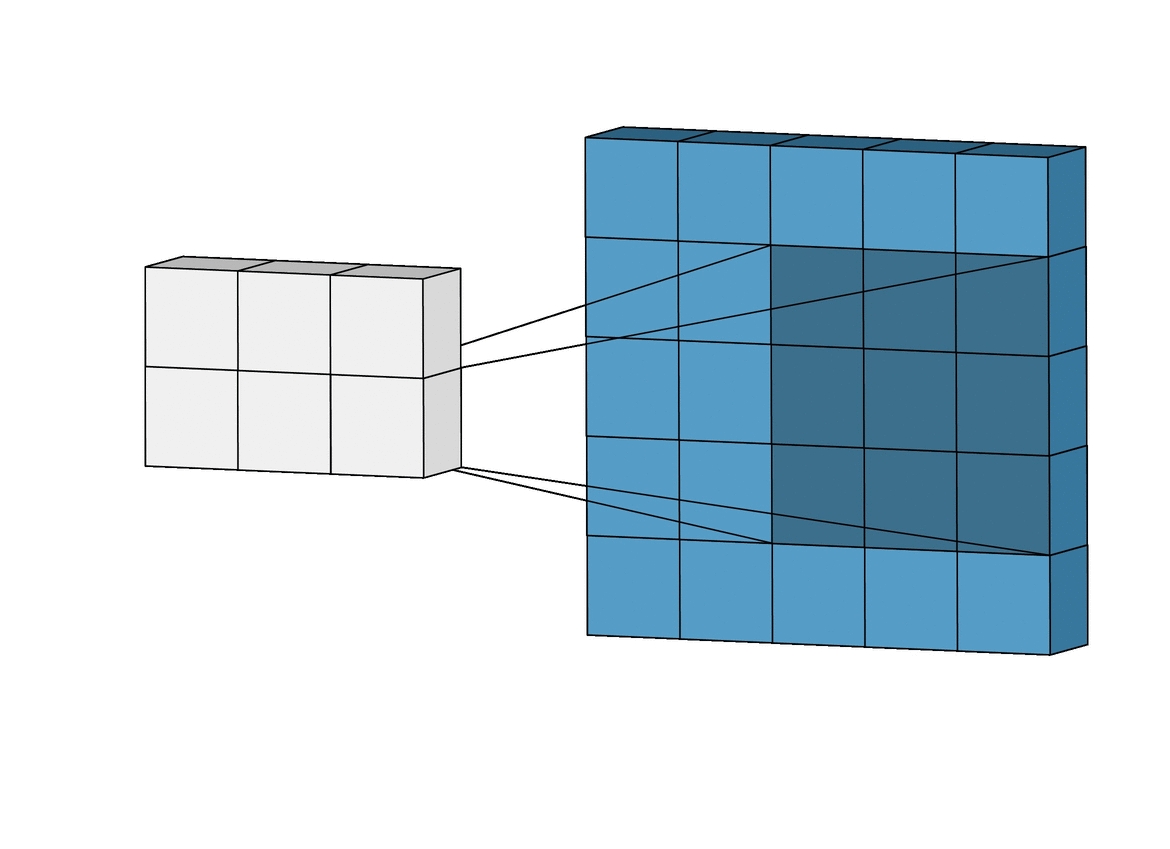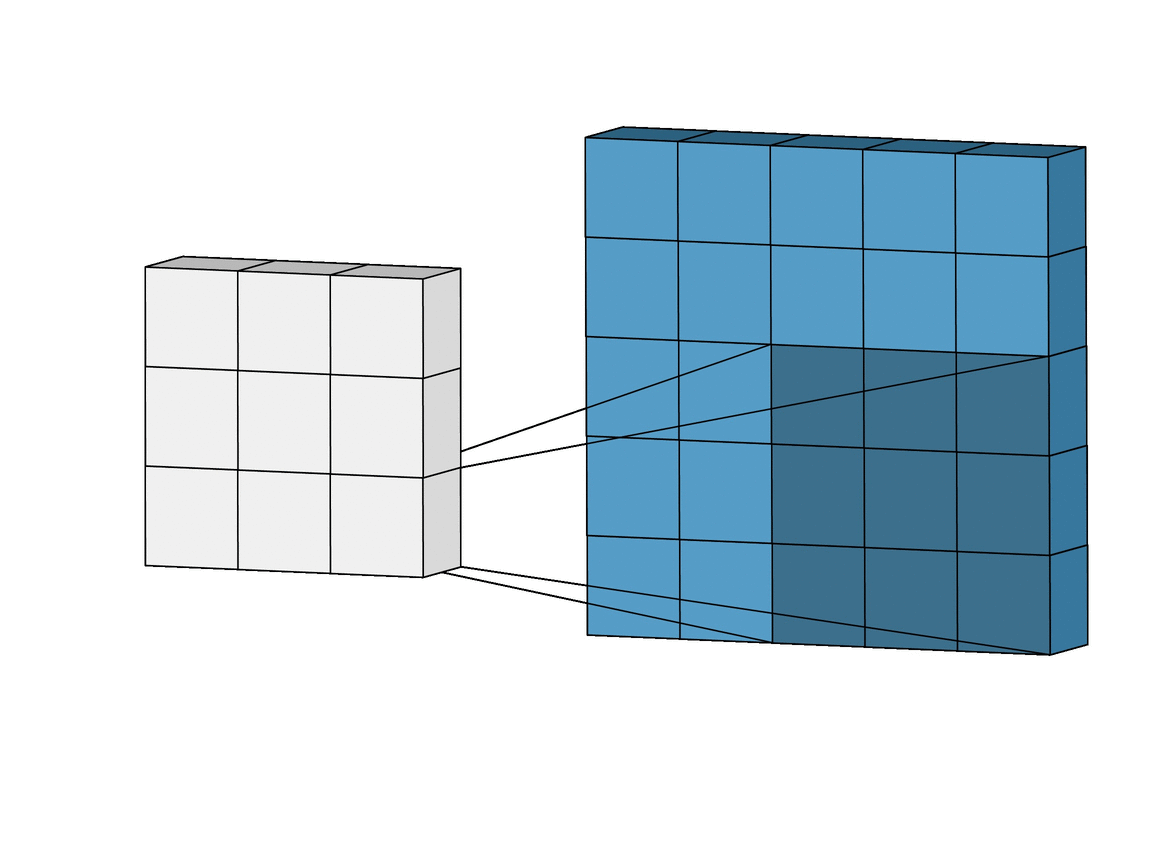
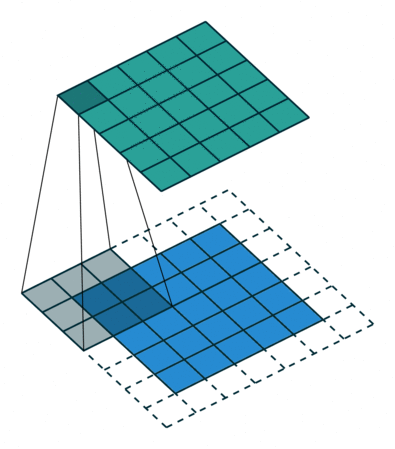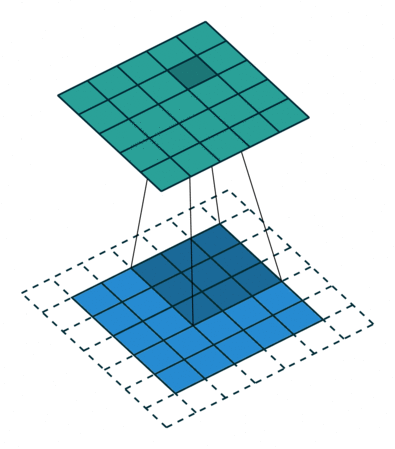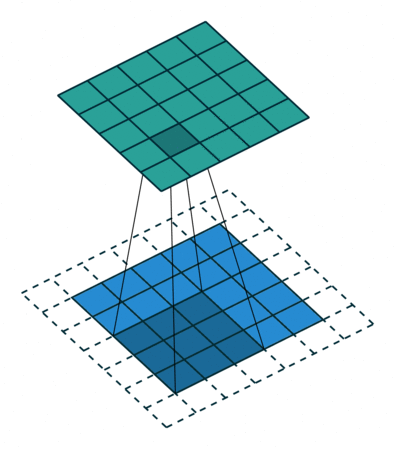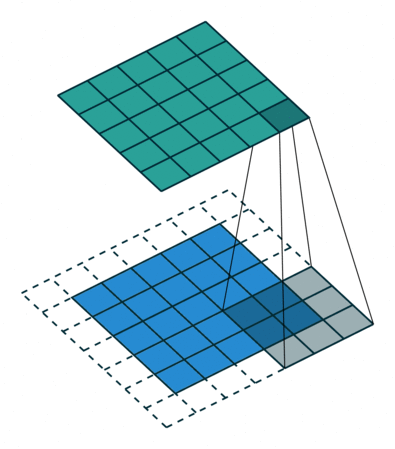
· 합성곱 신경망의 성능을 높이기 위해 여러개의 필터를 이용할 수도 있다. (※ 아래 그림 참고)
2. CNN의 구성
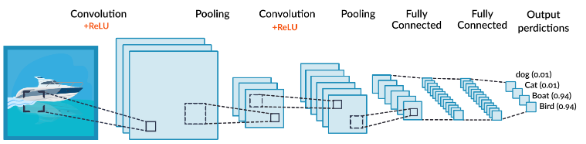
· 합성곱 신경망은 합성곱 계층(Convolution layer)과 완전연결 계층(Dense layer)을 같이 사용한다.
합성곱 계층 + 활성화 함수 + 풀링을 반복하면서 점점 크기가 작아지는데, 핵심적인 특성들을 뽑아내게 된다. 여기서 풀링 레이어(Pooling layer)는 특성 맵의 중요 부분을 추출하여 저장하는 역할을 한다.
1) Max pooling 예시
: 2x2 크기의 풀 사이즈(Pool size)로 스트라이드 2의 Max Pooling 계층을 통과할 경우 2x2 크기의 특성 맵에서 가장 큰 값들을 추출한다.

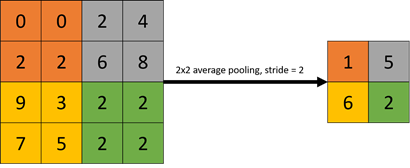
2) Average pooling 예시
: 2x2 크기의 풀 사이즈(Pool size)로 스트라이드 2의 Average Pooling 계층을 통과할 경우 2x2 크기의 특성 맵에서 평균 값 들을 추출한다.
· 아래 그림에서 두 번째 풀링을 지나게 되면 1차원의 완전연결계층(Fully Connected Layer)과 연결을 시켜야 하는데 Pooling을 통과한 특성맵은 2차원이기 때문에 연산이 불가하다.

· 이를 해결하기 위해 평탄화 계층(Flatten layer)을 사용해서 2차원을 1차원으로 펼치는 작업을 하게 된다.

· 평탄화 계층을 통과하게 되면 완전연결 계층에서 행렬곱셈을 할 수 있게 된다. 그리고 완전연결 계층(=Dense=Fully connected) + 활성화 함수의 반복을 통해 점점 노드의 갯수를 축소시키며, 마지막에 Softmax 활성화 함수를 통과하고 출력층으로 결과를 출력하게 된다.
3. CNN의 활용
· CNN은 아래와 같이 컴퓨터 비전 분야에서 사용되고 있다.
1) 물체 인식(Object Detection) : 사진 이미지에서 정확히 물체를 인식하는 것
2) YOLO (You Only Look Once) : 속도가 빠르다는 강점을 가졌고 다른 real-time detection에 비해 정확도가 높아 유명한 Computer Vision 알고리즘
3) 이미지 분할(Segmentation) : 각각의 오브젝트에 속한 픽셀들을 분리하는 것으로 나누는 기준이 디테일할 수록 정교화된 성능을 가져야하고 처리속도가 문제가 될 수 있다. 인물과 배경을 Focus를 위해 분리하거나, 의료 영상에서도 양성/음성 부분을 구분하는데 사용될 수 있다.
· CNN 활용 예
1) 자율주행 물체 인식 : Camera, Rader, LiDAR 등을 이용하여 객체를 인식 한 후 Image Classification 및 Localization을 확인
2) 자세 인식(Pose Detection) : 사람을 detect하고, 인체의 각 부분의 위치를 파악해 자세를 인식
3) 화질개선(Super Resolution)
4) Style Transfer : 이미지에 다양한 화풍을 적용
5) 사진 색 복원(Colorization) : 흑백사진을 컬러사진으로 변경 등(어느 부분이 얼굴인지, 건물인지 산인지 등을 인식)
4. CNN의 종류
· AlexNet(2012), VGGNet(2014), GoogLeNet(=Inception V3) (2015), ResNet (2015)

'DataScience > 머신러닝' 카테고리의 다른 글
| 머신러닝 :: 딥러닝 MNIST 실습_캐글 Sign Language 데이터셋(2)_CNN을 이용한 풀이 (0) | 2022.10.14 |
|---|---|
| 머신러닝 :: 딥러닝_전이학습, 순환신경망(RNN), 생성적 적대 신경망(GAN) (0) | 2022.10.13 |
| 머신러닝 :: 딥러닝 MNIST 실습_캐글 Sign Language 데이터셋 (0) | 2022.10.13 |
| 머신러닝 :: 딥러닝 XOR 예측 실습(이진 논리회귀, MLP, keras functional API) (0) | 2022.10.13 |
| 머신러닝 :: 딥러닝 주요 개념(배치, 활성화 함수, 과적합, 앙상블) (0) | 2022.10.13 |




댓글