
딥러닝 MNIST 실습_과일 종류 예측
1. 딥러닝 과일 사진을 통한 종류 예측
· 영어 알파벳 수화 데이터셋
(※ 링크 : https://www.kaggle.com/moltean/fruits)
1) 데이터셋 다운로드
import os
os.environ['KAGGLE_USERNAME'] = '<username>' # username
os.environ['KAGGLE_KEY'] = '<key>' # key!kaggle datasets download -d moltean/fruits
!unzip -q fruits.zip
2) 패키지 로드
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, Flatten, Dropout
from tensorflow.keras.optimizers import Adam, SGD
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder3) 이미지 증강 기법
- flow_from_directory 메소드를 사용하여 데이터셋이 저장된 폴더에서 직접 데이터를 읽어온다.
train_datagen = ImageDataGenerator( # ImageDataGenerator가 이미지를 로드
rescale=1./255, # 일반화
rotation_range=10, # 랜덤하게 이미지를 회전 (단위: 도, 0-180)
zoom_range=0.1, # 랜덤하게 이미지 확대 (%)
width_shift_range=0.1, # 랜덤하게 이미지를 수평으로 이동 (%)
height_shift_range=0.1, # 랜덤하게 이미지를 수직으로 이동 (%)
horizontal_flip=True # 랜덤하게 이미지를 수평으로 뒤집기
)
test_datagen = ImageDataGenerator(
rescale=1./255 # 일반화 # 테스트의 일관성을 높이기 위해 augmentation을 하지 않는다.
)
train_gen = train_datagen.flow_from_directory( # flow_from_directory를 사용하면 아래 경로('')의 폴더에서 알아서 읽어오고, 클래스별로 분류해준다.
'fruits-360/Training',
target_size=(224, 224), # (height, width)
batch_size=32,
seed=2021, # 랜덤 seed를 어떻게 섞을지
class_mode='categorical', # 라벨이 여러개일 때 -> categorical, 이진분류를 할 때 -> binary
shuffle=True
)
test_gen = test_datagen.flow_from_directory(
'fruits-360/Test',
target_size=(224, 224), # (height, width)
batch_size=32,
seed=2021,
class_mode='categorical',
shuffle=False
)
"""
Found 67692 images belonging to 131 classes.
Found 22688 images belonging to 131 classes.
"""from pprint import pprint
pprint(train_gen.class_indices)
preview_batch = train_gen.__getitem__(0) # 0번 배치의 아이템을 가져온다.
preview_imgs, preview_labels = preview_batch # 이미지, 라벨로 이루어져있다.
plt.title(str(preview_labels[0])) # 타이틀은 라벨을 문자형태로 바꾸어 출력
plt.imshow(preview_imgs[0]) # 이미지는 imshow로 출력
4) 전이 학습
https://keras.io/api/applications/
from tensorflow.keras.applications.inception_v3 import InceptionV3 # pretrained model을 위의 링크에서 찾아서 inceptionV3를 선정하여 임포트한다.
input = Input(shape=(224, 224, 3)) # 크기 -> 224*224, 컬러 -> 3
base_model = InceptionV3(weights='imagenet', include_top=False, input_tensor=input, pooling='max') # base_model(=back_born_model)은 inceptionV3를 사용한다.
# imagenet을 학습시키는 weights를 사용, include_top -> 마지막 출력 레이어를 이미 있는것을 쓸건지(True), 버릴껀지(False)
x = base_model.output
x = Dropout(rate=0.25)(x)
x = Dense(256, activation='relu')(x)
output = Dense(131, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
# 다항분류이기 때문에 categorical_crossentropy
model.summary()
5) 학습
ModelCheckpoint('model.h5', monitor='val_acc', verbose=1, save_best_only=True)
val_acc가 높은 1개의 모델(save_best_only)을 model.h5 라는 파일로 저장한다.
https://keras.io/api/callbacks/model_checkpoint/
from tensorflow.keras.callbacks import ModelCheckpoint
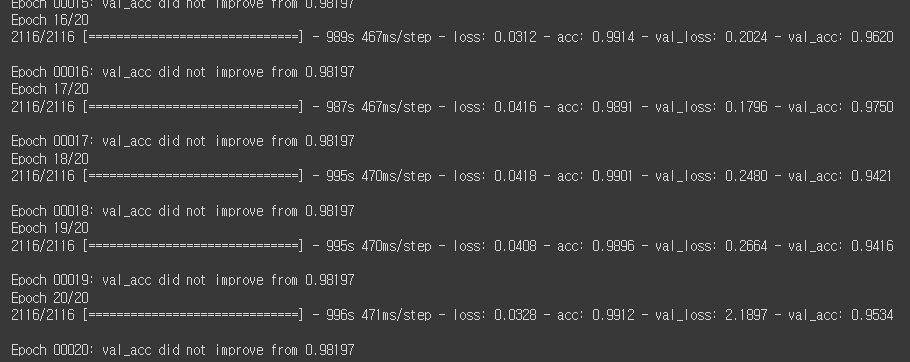
history = model.fit(
train_gen,
validation_data=test_gen, # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20, # epochs 복수형으로 쓰기!
callbacks=[
ModelCheckpoint('model.h5', monitor='val_acc', verbose=1, save_best_only=True)
]
)
6) 학습 결과 그래프
fig, axes = plt.subplots(1, 2, figsize=(20, 6))
axes[0].plot(history.history['loss'])
axes[0].plot(history.history['val_loss'])
axes[1].plot(history.history['acc'])
axes[1].plot(history.history['val_acc'])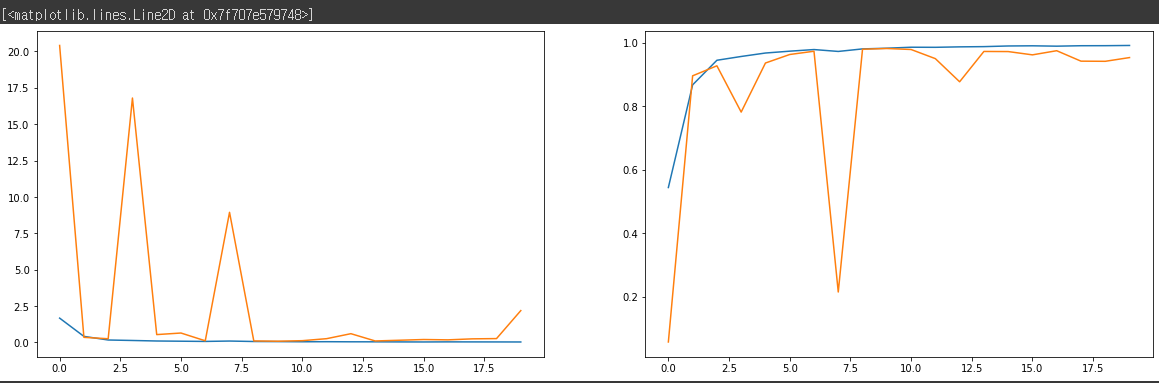
7) 학습된 모델 로드
from tensorflow.keras.models import load_model
model = load_model('model.h5')
print('Model loaded!')
"""
Model loaded!
"""8) 테스트
test_imgs, test_labels = test_gen.__getitem__(100)
y_pred = model.predict(test_imgs)
classes = dict((v, k) for k, v in test_gen.class_indices.items())
fig, axes = plt.subplots(4, 8, figsize=(20, 12))
for img, test_label, pred_label, ax in zip(test_imgs, test_labels, y_pred, axes.flatten()):
test_label = classes[np.argmax(test_label)] # one-hot encoding에서 반대로 바꾸어줄 때
pred_label = classes[np.argmax(pred_label)]
ax.set_title('GT:%s\nPR:%s' % (test_label, pred_label))
ax.imshow(img)
# GT : Ground Truth(정답값), PR : Prediction Truth(예측값)
반응형
'DataScience > 머신러닝' 카테고리의 다른 글
| Web 개발 :: 프로젝트 조회수, Permission, Dataframe, 머신러닝_TIL66 (0) | 2022.12.07 |
|---|---|
| 파이썬 웹 프로그래밍 :: 10월 셋째주 WIL #07 (0) | 2022.10.20 |
| 머신러닝 :: 딥러닝 MNIST 실습_캐글 Sign Language 데이터셋(2)_CNN을 이용한 풀이 (0) | 2022.10.14 |
| 머신러닝 :: 딥러닝_전이학습, 순환신경망(RNN), 생성적 적대 신경망(GAN) (0) | 2022.10.13 |
| 머신러닝 :: 합성곱 신경망(CNN, Convolutional Neural Networks) (0) | 2022.10.13 |




댓글