■ JITHub 개발일지 34일차

□ TIL(Today I Learned) ::
파이썬 머신러닝_Yolov5을 활용한 이미지 검출
· 사진에서 과일을 인식시키는 머신러닝 모델을 생성한다. 이를 위해 Yolov5, 그리고 OpenCV를 활용하였다.
· 모델 학습은 colab을 사용하였다. VSCode를 사용할 수도 있지만 colab을 통해 진행했다.
· 사용할 데이터셋은 Roboflow라는 사이트에서 받을 수 있었다. 어제 썼던 kaggle 데이터셋보다 나아보였다.
아래와 같이 커맨드를 입력해서 데이터셋을 압축파일로 받아오고, 압축을 풀어 사용할 수 있다.
!curl -L "https://public.roboflow.com/ds/a6SqTvZHdj?key=3pqf4RvUae" > roboflow.zip; unzip roboflow.zip; rm roboflow.zip· yolov5를 colab에서 사용할 때에는 github에서 클론받아와 사용할 수 있다. 디렉터리는 content이다.
%cd /content/
!git clone https://github.com/ultralytics/yolov5.git· yolov5에는 라이브러리가 정말 많다. requirements.txt를 체킹해서 설치해준다.
%cd /content/yolov5/
!pip install -r requirements.txt· 받아온 데이터셋이 어떻게 이루어져있는지는 data.yaml 파일을 미리 확인해보면 알 수 있다.
%cat /content/dataset/data.yaml
train: ../train/images
val: ../valid/images
nc: 63
names: ['Apple', 'Apricot', 'Avocado', 'Banana', 'Beetroot', 'Blueberry', 'Cactus', 'Cantaloupe', 'Carambula', 'Cauliflower', 'Cherry', 'Chestnut', 'Clementine', 'Cocos', 'Dates', 'Eggplant', 'Ginger', 'Granadilla', 'Grape', 'Grapefruit', 'Guava', 'Hazelnut', 'Huckleberry', 'Kaki', 'Kiwi', 'Kohlrabi', 'Kumquats', 'Lemon', 'Limes', 'Lychee', 'Mandarine', 'Mango', 'Mangostan', 'Maracuja', 'Melon', 'Mulberry', 'Nectarine', 'Nut', 'Onion', 'Orange', 'Papaya', 'Passion', 'Peach', 'Pear', 'Pepino', 'Pepper', 'Physalis', 'Pineapple', 'Pitahaya', 'Plum', 'Pomegranate', 'Pomelo', 'Potato', 'Quince', 'Rambutan', 'Raspberry', 'Redcurrant', 'Salak', 'Strawberry', 'Tamarillo', 'Tangelo', 'Tomato', 'Walnut']· 아래와 같이 glob를 사용하면 해당 폴더안의 모든 파일들을 받아와 리스트로 저장할 수 있었다! (몰랐던 사실!)
내가 사용한 데이터는 이미지가 5000개였다.
%cd /
from glob import glob
img_list = glob('/content/dataset/train/images/*.jpg')
print(len(img_list))
"""
/
5000
"""· 트레이닝셋 80%, 테스트셋 20%로 이미지를 쪼개어주었다. 각각 4000개 1000개이다.
# 트레이닝 셋과 테스트 셋을 나눈다.
from sklearn.model_selection import train_test_split
train_img_list, val_img_list = train_test_split(img_list, test_size=0.2, random_state=2000)
print(len(train_img_list), len(val_img_list))
"""
4000 1000
"""· 각 폴더에 있는 이미지들을 train, val 나누어서 텍스트파일에 경로들을 모두 저장한다.
with open('/content/dataset/train.txt', 'w') as f:
f.write('\n'.join(train_img_list)+'\n')
with open('/content/dataset/val.txt', 'w') as f:
f.write('\n'.join(val_img_list)+'\n')· 위의 경로가 담긴 텍스트파일을 yaml 파일에 적용해준다. 이렇게 하면 학습 준비가 끝이난다.
import yaml
with open('/content/dataset/data.yaml', 'r') as f:
data = yaml.full_load(f)
print(data)
data['train'] = '/content/dataset/train.txt'
data['val'] = '/content/dataset/val.txt'
with open('/content/dataset/data.yaml', 'w') as f:
yaml.dump(data,f)
print(data)
· 이제 학습을 진행하면 된다. 아래는 이미지 사이즈 416, 배치 사이즈 16, 에폭 50, data.yaml 경로, configuration, weights 파일, 사용할 yolov5의 weight파일(크기별로 있다. l, m, n, s, x). 저장되는 경로 이름 이렇게 옵션지정을 해준다.
%cd /content/yolov5/
!python train.py --img 416 --batch 16 --epochs 50 --data /content/dataset/data.yaml --cfg ./models/yolov5s.yaml --weights yolov5s.pt --name fruits_yolov5s_results· 인고의 시간이 지나니 이렇게 학습이 끝나고, last.pt, best.pt라는 모델을 만들어준다.
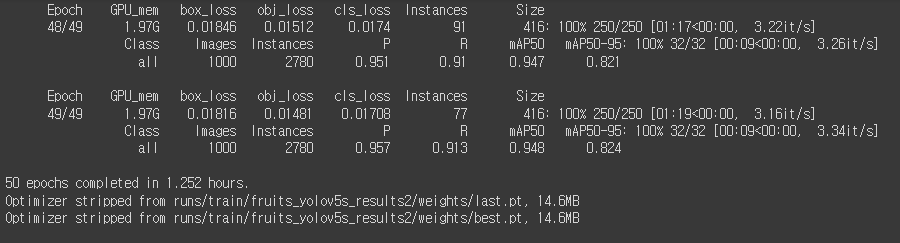
· 텐서 보드를 활용해서 학습이 어떻게 되었는지 시각화해 볼 수도 있다.
%load_ext tensorboard
%tensorboard --logdir /content/yolov5/runs/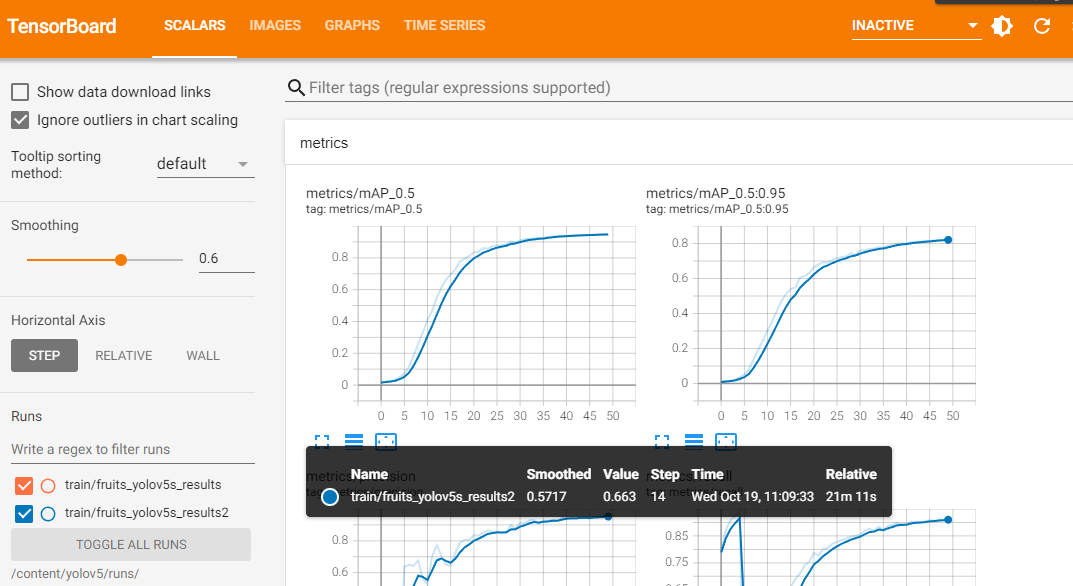
· 이제 학습은 잘 되었고 검증하면 된다. 아래와 같이 입력하여 검증할 수 있다.
사실 코랩에서 이렇게 진행하고, 나중에 장고에 적용할 때 헤맸다. 터미널 입력인데?? 장고에 어떻게 적용하지??
from IPython.display import Image
import os
val_img_path = val_img_list[0]
!python detect.py --weights /content/yolov5/runs/train/fruits_yolov5s_results2/weights/best.pt --img 416 --conf 0.5 --source "{val_img_path}"· 이미지도 보고싶으면 아래 코드를? 그런데 이상하게 실행결과에 에러가 났다.
Image(os.path.join('/content/yolov5/runs/detect/', os.path.basename(val_img_path)))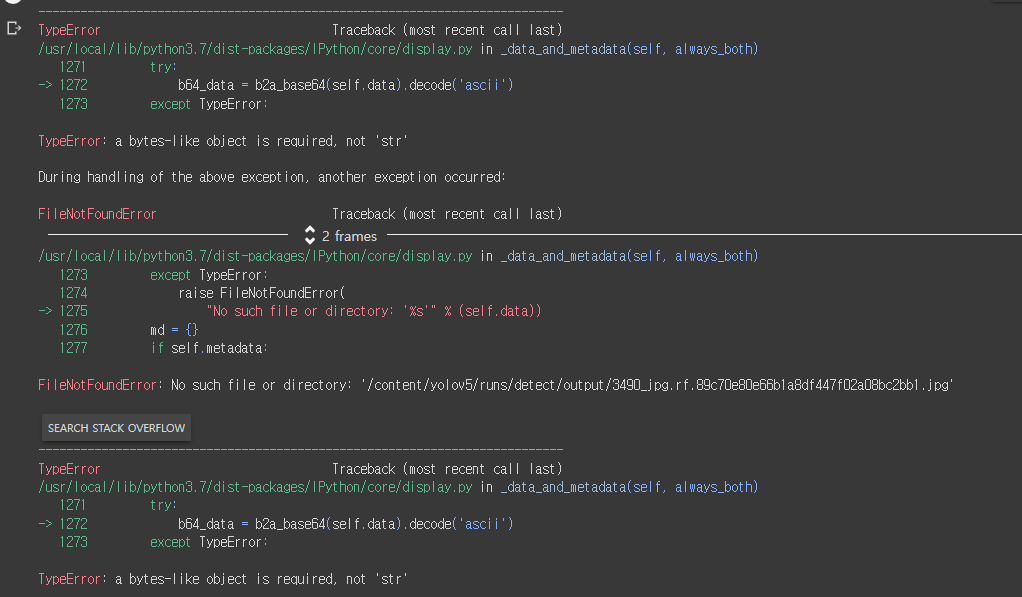
· 일단 파이썬에 적용하는 것이 중요하니 제쳐두기로 했다.
· 어? 그런데 진짜 터미널 명령어 어떻게 파이썬으로 실행하지?? 라는 생각이 문득 들었다.
다른 방법을 찾아보았다.
· 일단 내가 학습시킨 소중한 모델은 들고와야겠다. 아래 코드처럼 쓰면 로컬 경로에 저장된 모델(best.pt)을 들고온다.
model = torch.hub.load('ultralytics/yolov5', 'custom', path='model_det/best.pt', force_reload=True)· 모델을 가져오고, 사용할 이미지를 로드하고, 모델에 넣어서 검사하고 저장할 리스트도 지정하고...
이 모든 작업을 하기 위한 함수는 일단 아래와 같이 짰다.
def pick_img(img_url):
img = cv2.imread(img_url) # 이미지 불러오기
results = model(img) # 이미지 검사
img_detected = list() # 이미지 검사 후 저장할 리스트 지정
results.save()
result = results.pandas().xyxy[0].to_numpy()
for item in result:
try:
if item[6] in fruit_model:
img_detected.append(item[6]) # 이미지 이름 추출
except:
return redirect('post:post-create-img',{'error':'재료를 찾을 수 없습니다.'})
picked = random.choice(img_detected) # 추출한 과일이름 중 하나 선택
return redirect('post:post-create',picked=picked)· 지금 아직 남아있는 문제들이 있는데 그건 아래에 정리해보겠다.
1) 문제점 : 어떤 문제가 있었는지?
· 현재 남아있는 문제점이다.
1) 아래의 3가지 단계에 따라 동작이 되어야 한다.
① 게시글에서 사진을 업로드하고 이를 검사한다. 이때 method는 POST
② 검사가 완료된 사진은 어떤 과일인지 이름을 추출하여 이전에 작성하던 내용들과 함께 게시글 생성 템플릿에 보내준다. method GET
③ 나머지 내용 작성하여 저장한다. method POST
2) 검사를 마친 사진이 저장될 공간을 지정해야 한다. 현재는 run/exp에 계속 쌓이는 구조이다.
3) 검사 완료 후 출력된 재료의 이름을 보내주어야 한다.
4) 게시글이 생성되면 재료 이름에 따라 관련 레시피를 추천해주어야 한다.
5) 위의 모든 항목이 동작되기 위해 지금 짜놓은 코드들을 다 개비해야 한다.
머신러닝 부분때문에 나머지 코드들을 건드리다 사고날까 좀 두렵긴하다. 깃 커밋...PR 후 병합하기가 정말 두렵다..
· pip 업그레이드를 하려했으나 권한문제로 인해 업그레이드 전 pip가 기존 버전을 삭제하고 신규로 설치하지 못해 에러가 났다. 이 때문에 python을 3번이나 재설치했다.
2) 몰랐던 점, 알게된 점 또는 해결
· cv2 라이브러리 설치할 때에는 pip install opencv-python 으로 설치!
· 파이썬 설치할 때 첫 화면에서 맨 아래 체크박스 설치해주면 환경변수 설정안해도 되었다. 굳굳
· 코랩은 런타임 GPU 설정안하면 시간 엄청 잡아먹는다.
· 이 외에도 너무 많은데 앞으로는 더 잘 기록해야겠다.
'DEV > Web 개발' 카테고리의 다른 글
| Web 개발 :: 머신러닝 프로젝트_TIL#35 (0) | 2022.10.23 |
|---|---|
| Sparkling Coffee Club :: 머신러닝 웹 개발 프로젝트 KPT 회고록 (0) | 2022.10.21 |
| Web 개발 :: 머신러닝 프로젝트 SA_TIL#33 (0) | 2022.10.20 |
| Web 개발 :: 파이썬 Django 인스타그램 코드 리뷰, 머신러닝_TIL#31 (0) | 2022.10.18 |
| Web 개발 :: 파이썬 django 인스타그램 코드 리뷰, 머신러닝 (0) | 2022.10.14 |




댓글