
파이썬 웹 프로그래밍 _ 파이썬 웹 크롤링, 몽고디비(MongoDB)
들어가면서..
이제 웹에 있는 자료들을 가져와 데이터베이스에 저장하고 이를 활용하고자 한다.
1. html 기본 구조(ajax)
· 웹에 저장된 OPEN API 자료를 활용하기 위한 html ajax function 함수 구조
(1) type : 데이터를 'GET' 타입으로 받아올 것인지, 'POST' 타입으로 받아올 것인지?
(2) url : 대상이 될 API의 url 주소
(3) data : 교환할 Data
(4) success : 함수 실행시 동작되는 기능
$(document).ready(function(){
listing();
});
function listing() {
$.ajax({
type: "GET",
url: "http://spartacodingclub.shop/web/api/movie",
data: {},
success: function(response){
let movies = response['movies']
for (let i = 0 ; i < movies.length; i++) {
let movie = movies[i]
let title = movie['title']
let desc = movie['desc']
let image = movie['image']
let comment = movie['comment']
let star = movie['star']
let star_image = '⭐'.repeat(star)
let temp_html = `<div class="col">
<div class="card h-100">
<img src="${image}" class="card-img-top">
<div class="card-body">
<h5 class="card-title">${title}</h5>
<p class="card-text">${desc}</p>
<p>${star_image}</p>
<p class="mycomment">${comment}</p>
</div>
</div>
</div>`
$('#cards-box').append(temp_html)
}
})
}· 코드 분석
1) 'GET' 타입으로 지정된 API에서 데이터를 가져오며,
2) App.py에서 GET으로 받아온 response, 'movies'(리스트)를 movies라는 리스트 변수에 넣는다.
3) for 문을 돌려서 각 항목별 빼내온 데이터들을 변수에 넣고,
4) temp_html이라는 동적 변수에서 정의하고 있는 동작(` `, 백틱 내부)에 따라 '#cards-box'에 추가하고
5) i +1을 한 다음, for 문으로 돌아온다.
· 기존에 있던 데이터들을 지우고 시작할 때는 다음과 같이 코드를 사용한다.
$('#cards-box').empty('');2. 파이썬 패키지 설치하기
· 패키지 : 모듈(일종의 기능들 묶음)을 모아 놓은 단위
· 라이브러리 : 패키지를 모아 놓은 단위
· 신규 프로젝트 생성시 'venv' 폴더?
: venv = 가상환경(virtual environment) : 패키지를 담는 폴더
· 파이참을 사용하는 경우 패키지를 설치하려면,
▷ 설정 → 프로젝트 → Python 인터프리터 → '+' 버튼 → 필요한 패키지 검색 → '패키지 설치'
※ requests 패키지 사용 예시▽
- 미세먼지가 60이하인 구의 이름과 미세먼지 수치 출력
import requests # requests 라이브러리 설치 필요
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
gus = rjson['RealtimeCityAir']['row']
for gu in gus:
if gu['IDEX_MVL'] < 60:
print (gu['MSRSTE_NM'], gu['IDEX_MVL'])3. 웹 스크래핑(크롤링) 기초
· 샘플로 네이버 영화 페이지를 웹스크래핑(크롤링) 해볼까?
- 활용할 페이지 주소 : https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829
- 패키지 추가 설치(requests, bs4) : requests와 beautifulsoup4 패키지를 사용할 예정
- 크롤링 기본 셋팅(import)
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup(data.text, 'html.parser')
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가되었으며, 이제 필요한 부분을 추출하면 된다.
#############################
# (입맛에 맞게 코딩)
#############################- 아래는 네이버 영화 페이지를 접속한 모습이다.

· 필요하다고 생각되는 데이터 (ex. 밥정, 9.64 ..)에 마우스를 위치하고 우클릭 → 검사를 클릭한다.

· Dev Tools가 위와 같이 열리고 선택한 부분이 파란색으로 하이라이팅 된 것을 볼 수 있다.
원하는 데이터(ex. 밥정) 위에서 우클릭 → 복사(copy) → selector 복사(copy selector) → 메모장에 붙여넣기
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a위와 같은 경로 data를 얻을 수 있다.
똑같은 방식으로 원하는 데이터(영화명)의 2순위 그린 북도 selector를 추출하면
#old_content > table > tbody > tr:nth-child(3) > td.title > div > a여기서 우리는 "#old_content > table > tbody > tr" 까지의 주소는 동일하다는 것을 알 수 있으며
구분된 주소까지가 "영화명" 이라는 항목의 카테고리 주소임을 예측할 수 있다.
# select를 이용해서, tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr')
# movies (tr들)의 반복문
for movie in movies:
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None: # movie 안에 a 가 있으면,
print (a_tag.text) # a의 text를 찍어본다.순위에 있는 각 영화명 데이터들을 불러올 수 있다.
# 선택자를 사용하는 방법 (copy selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
# 한 개만 가져오고 싶은 경우
soup.select_one('태그명[속성="값"]')
※ 실습. '순위', '제목', '별점' 까지 크롤링해오기
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#old_content > table > tbody > tr:nth-child(3) > td.title > div > a
#old_content > table > tbody > tr:nth-child(4) > td.title > div > a
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None:
title = a.text
rank = movie.select_one('td:nth-child(1) > img')['alt']
star = movie.select_one('td.point').text
print(rank, title, star)4. Database 개요
· RDBMS(SQL) : 행/열이 있는 정형화된 Database (ex. MS-SQL, MySQL 등)
· No-SQL : 딕셔너리형태로 데이터가 저장되는 Database. 자유로운 형태의 데이터 적재에 유리하나 일관성이 부족할 수 있음 (ex. MongoDB 등)
5. MongoDB 사용하기
(1) MongoDB 사이트에서 계정 생성
(2) Project 생성 : 프로젝트 명 지정 → add members, Set Permissions → Create Project 선택
(3) Database 생성 : Shared 버전 선택하고 Create → (Language : Python, cloudDB : Shared, Provider : aws, Region : Seoul) → Create Cluster → user name, password 생성 후 create User → Allow Access from Anywhere → Add IP address → Database User 생성 → Choose a connection method
(4) Cluster 연결하기 : Connect → Allow Access from Anywhere → Add IP address → Choose a connection method → Connect your application 클릭 → Select driver and version(driver → Python, Version → 3.6 or later··) → application code 복사



(5) MongoDB Atlas 연결하기
- 파이참에서 pymongo, dnspython 패키지 설치
- 아래 import Code를 App.py에 입력하고, (3)의 application code 붙여넣기
※ pymongo 기본 코드(import)
· 아래 코드에 application code 입력 후 잘 연결되었는지 Test 해본다.
from pymongo import MongoClient
client = MongoClient('여기에 application code 입력')
db = client.dbsparta
doc = {
'name':'bob',
'age':27
}
db.users.insert_one(doc)· Cluster의 Collections에 'users'라는 이름의 데이터 베이스에 doc의 데이터가 잘 들어왔는지 확인해본다.
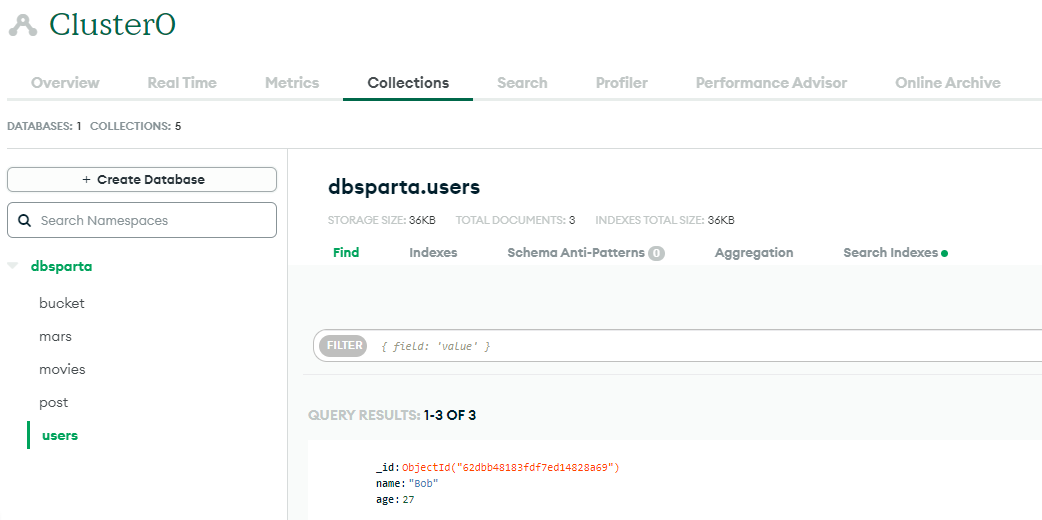
※ pymongo에서 자주 사용되는 Code
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
all_users = list(db.users.find({},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})
※ 실습. 지니뮤직의 1~50위 곡 스크래핑 해보기
- 참고링크 : https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
songs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for song in songs:
title = song.select_one('td.info > a.title.ellipsis').text.strip()
if "19금" in title:
title = song.select_one('td.info > a.title.ellipsis').text.strip().lstrip('19금').strip()
rank = song.select_one('td.number').text[0:2].strip()
singer = song.select_one('td.info > a.artist.ellipsis').text.strip()
print(rank, title, singer)
else:
title = song.select_one('td.info > a.title.ellipsis').text.strip()
rank = song.select_one('td.number').text[0:2].strip()
singer = song.select_one('td.info > a.artist.ellipsis').text.strip()
print(rank, title, singer)< 결과 화면 >

'DEV > Web 개발' 카테고리의 다른 글
| 파이썬 웹 프로그래밍 :: html/CSS 스타일, 소개 페이지 제작_TIL#01 (2) | 2022.08.29 |
|---|---|
| 파이썬 웹 프로그래밍 :: aws 활용 웹 퍼블리싱 (0) | 2022.07.24 |
| 파이썬 웹 프로그래밍 :: 파이썬 플라스크(Flask) 서버 제작, API 생성, Client 연결 (0) | 2022.07.24 |
| 파이썬 웹 프로그래밍 :: jQuery, Ajax를 활용한 웹 화면 생성 (0) | 2022.07.22 |
| 파이썬 웹 프로그래밍 :: HTML, CSS 기본개념 (0) | 2022.07.12 |




댓글