■ JITHub 개발일지 44일차

□ TIL(Today I Learned) ::
DRF, 추천 시스템(코사인 유사도, TF-IDF) 구현
- 현재 프로젝트에서는 사용자에게 임의의 노래 리스트를 보여주고, 사용자가 노래를 선택하면 추천해주는 서비스를 제공한다. 지난번에 머신러닝을 담당했던 것을 연장해서 이번에도 추천 시스템 기능 구현을 담당하게 되었다.
- 앱은 recommend라는 이름의 앱을 새로 생성하여 작업했다. 이번에는 DRF를 사용하기 때문에 Back-end 부분이랑 Front-end부분을 분리하여 작업하고 있다.
- 추천 기능은 django의 views.py에 넣지않고, 별도로 분리된 파일을 생성하여 작성했다.
(이름은 recommend_function.py로 하였다.)
- django에서는 manage.py에서 startapp을 통해 생성한 파일이 아닌, 별도의 파일을 생성하여 사용할 때 문제가 발생하는 경우가 있다. 특히 이번에는 songs라는 앱의 Song이라는 모델을 import하기 위해서 아래와 같이 작성했는데 임포트하지 못하는 문제가 발생했다.
# recommend/recommend_function.py
from songs.models import Song- 몇 번을 다시 보아도 문제가 보이지 않았는데, 알고 보니 별도의 설정이 필요하였다. 아래와 같이 시스템 관련 모듈들을 임포트해오고, 환경설정을 통해 django에게 새로운 파일이 생성되어있음을 알려주어야 한다.
# recommend/recommend_function.py
import sys
import os
import django
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR)
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'Music_Recommend.settings')
django.setup()- 추천 시스템을 구현할 때에도 문제가 많았다.
- 일단 우리 프로젝트는 아이템 기반 협업 필터링이라고 생각하고 작업을 하였다.
- 데이터를 불러올 때에는 처음에는 갖고 있던 csv나 json파일을 경로로부터 사용했지만, 나중에 배포할 것을 생각하면 데이터베이스에 있는 자료들을 불러오도록 해주어야 했다.
ratings = pd.read_csv('ratings.csv')
movies = pd.read_csv('movies.csv')
# 데이터프레임을 출력했을때 더 많은 열이 보이도록 함
pd.set_option('display.max_columns', 10)
pd.set_option('display.width', 300)
# movieId를 기준으로 ratings 와 movies 를 결합함
movie_ratings = pd.merge(ratings, movies, on='movieId')
print(movie_ratings)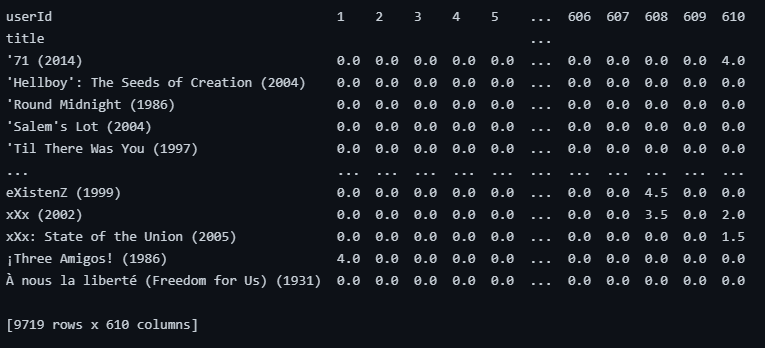
- 각 영화는 행 이름으로, 유저는 열 이름으로 하고, 평점이 값으로 하는 피봇테이블을 만들어준다.
# 이번에는 Index에 title이 들어감!
user_title = movie_ratings.pivot_table('rating', index='title', columns='userId')
user_title = user_title.fillna(0)
print(user_title)- 두 영화에 대한 관계를 코사인 유사도로 표현하기 위하여 아래와 같이 작성한다.
from sklearn.metrics.pairwise import cosine_similarity
item_based_collab = cosine_similarity(user_title, user_title)
print(item_based_collab)
- 결과를 아래 코드를 통해 데이터프레임으로 변환해주었다.
item_based_collab = pd.DataFrame(item_based_collab, index=user_title.index, columns=user_title.index)
print(item_based_collab)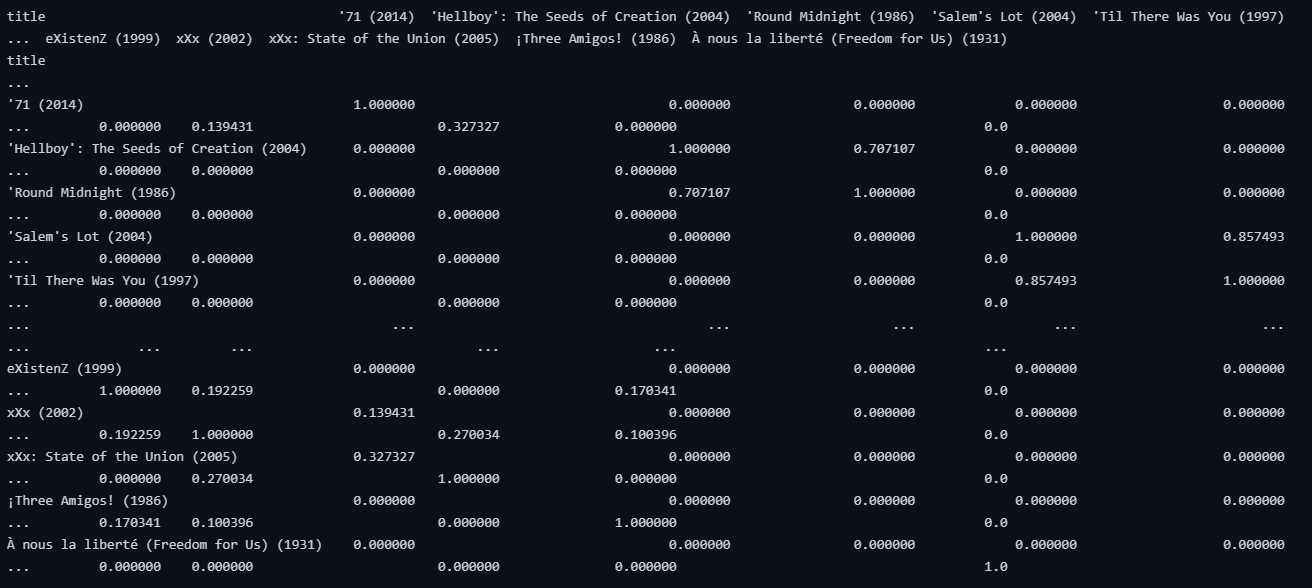
- 샘플 테스트를 해보고, 결과가 잘 나왔는지 확인한다.
# 다크나이트와 비슷하게 유저들로부터 평점을 부여받은 영화들은?
print(item_based_collab['Dark Knight, The (2008)'].sort_values(ascending=False)[:10])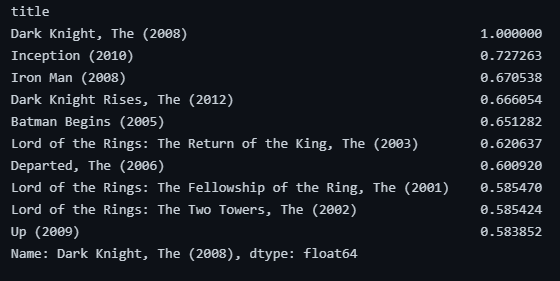
- 위와 같은 방법을 사용할 수도 있지만, 이번 프로젝트는 다른 방식을 사용하기로 했다.
- TF-IDF(Term Frequency - Inverse Document Frequency)를 통해 노래의 가사를 분석하여 두 곡 사이에서 단어의 유사도가 얼마나 나타나는지 코사인 유사도를 통해 비교하고 가장 유사한 20개의 곡을 추천해주는 방식이다.
*TF-IDF : 정보 검색과 텍스트 마이닝에서 이용하는 가중치로, 여러 문서로 이루어진 문서군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치 [위키백과]
- 가장 먼저 위의 환경설정과 사용할 모듈들을 임포트해오고, DB에서 데이터를 가져온다.
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.feature_extraction.text import CountVectorizer
from songs.models import Song
# DB에서 데이터 가져오기
data = pd.DataFrame(list(Song.objects.values()))- 만약 DB가 아닌 json파일로 가져올 경우 아래와 같이 사용한다.
data = pd.read_json('./rawdata.json') # json파일로 실행할 경우- 사전에 null값이 있는지 확인해준다.
data['lyrics'].isnull().sum() # null 값이 있는지 확인(있다면 오류 발생함)- TF-IDF를 수행하여 각 가사에 있는 단어들을 분석하여 벡터화한다.
# lyrics에 대해서 tf-idf(Term Frequency - Inverse Document Frequency) 수행
tfidf = TfidfVectorizer()
tfidf_matrix = tfidf.fit_transform(data['lyrics'])- 코사인 유사도(cosine similarity)를 계산한다.
cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix) # 코사인 유사도 계산
indices = pd.Series(data.index, index=data['title']).drop_duplicates() # 노래 타이틀과 인덱스 받아오기- 추천 기능을 실제로 구동할 함수를 생성한다.
# 추천기능 함수 생성
def get_recommendations(idx, cosine_sim=cosine_sim):
sim_scores = list(enumerate(cosine_sim[int(idx)])) # 모든 노래에 대해 해당 노래와의 유사도를 연산
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True) # 유사도에 따라 노래들을 정렬
sim_list = sim_scores[1:21] # 가장 유사한 20개 노래의 인덱스와 score를 받아옵니다.
new_list = []
for i in sim_list:
new_dict = dict()
new_dict['pk'] = i[0]
new_dict["title"] = data['title'].iloc[i[0]]
new_dict["singer"] = data['singer'].iloc[i[0]]
new_dict["image"] = data['image'].iloc[i[0]]
new_list.append(new_dict)
return new_list- 코드를 작성 후 바로바로 확인하기 위해 테스트 문구를 적어주었다.
# 테스트
x = int(input("입력하세요:"))
result = get_recommendations(x)
print(result)- 위의 과정을 거치면서 몇몇 오류를 만났지만, 가장 어이없었던 부분은 추천기능 함수를 생성할 때 리스트 내에 딕셔너리를 중첩해서 넣어주는 코드에서 발생했었다. 아래 코드에서 return은 최종적으로 list를 해주어야 한다. 그런데.. for문 안에있던 dict를 리턴해주고 있었다.
def list_create(...)
new_list = []
for i in list:
new_dict = dict()
new_dict['pk'] = i[0]
new_list.append(new_dict)
return new_list이 오류를 기억하기 위해 아래와 같이 정리했다.
1) 리스트는 for문 밖에서 정의해주어야 한다. for문 내에서 정의해줄 시, for문을 반복할 때마다 리셋되게 된다.
2) list 내부에 들어갈 딕셔너리는 for문 내부에서 정의하고, 딕셔너리에 들어갈 값들이 모두 차면 리스트에 append해준다.
3) 함수를 사용했다면, return시 딕셔너리가 아닌 리스트를 리턴할 수 있도록 주의한다.
'DEV > Web 개발' 카테고리의 다른 글
| Web 개발 :: 파이썬 Django Rest Framework(12) _ Serializer 보완(Likes count, Comments count) (0) | 2022.11.05 |
|---|---|
| Web 개발 :: 파이썬 Django Rest Framework(11) _ 좋아요, 팔로우 기능 (0) | 2022.11.04 |
| Web 개발 :: 파이썬 Django Rest Framework(10) _ 댓글 CRUD (0) | 2022.11.03 |
| Web 개발 :: Django rest framework, csv to json_TIL#43 (0) | 2022.11.03 |
| Web 개발 :: 노래 추천 서비스 프로젝트 SA (0) | 2022.11.02 |




댓글