
파이썬 불러오기(.txt), strip, split
1. 텍스트 파일(.txt) 불러오기(읽기)
저장된 텍스트 파일을 불러오려면 아래와 같이 with open문을 사용한다
with open('경로/파일명', 'r') as 변수명:여기서 경로가 동일할 경우 '/파일명' 으로 사용이 가능하다.
'r'은 읽기(read) 모드를 나타낸다. (* 자세한 내용 링크 참고)
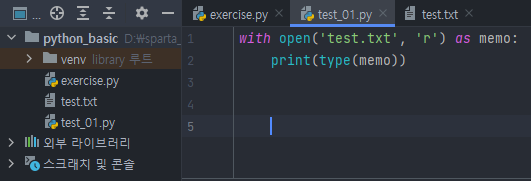
아래와 같이 타입을 출력하면 <class '_io.TextIOWrapper'> 가 나타난다. 알고있는 자료형이 아니다.
with open('test.txt', 'r') as memo:
print(type(memo))
>>> <class '_io.TextIOWrapper'>저장된 텍스트 파일은 아래와 같이 리스트로 만들어 사용이 가능하다.
with open('test.txt', 'r') as memo:
for line in memo:
print(line)그러나 실행시 아래와 같은 오류가 발생하였다.

UnicodeDecodeError: 'cp949' ... 찾아보니 cp949 코덱으로 인코딩 된 파일을 읽어들일 때 발생할 수 있는 문제라고 한다.
이는 아래와 같이 UTF8로 인코딩을 지정하여 호출하면 에러가 사라진다.
with open('test.txt', 'r', encoding='UTF8') as memo:
for line in memo:
print(line)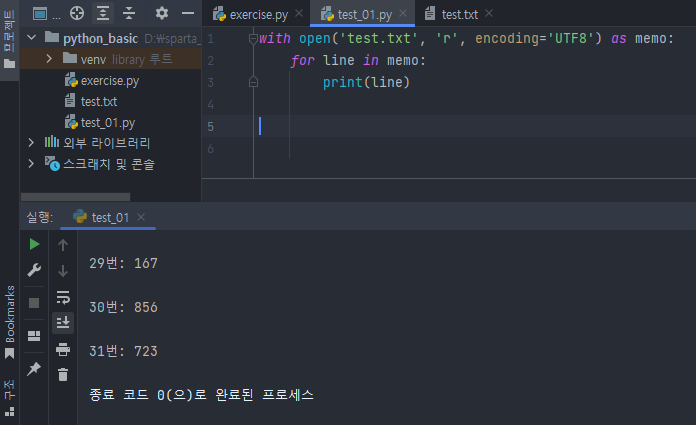
2. 텍스트 파일(.txt) 불러오기(쓰기)
파일쓰기도 파일 읽기랑 같이 with open문을 활용한다.
차이점은 읽기는 open('파일명', 'r') 이었다면 쓰기는 open('파일명', 'w')를 사용한다. w는 쓰기(Write)의 약자이다.
with open('new_file.txt, 'w') as f:
f.write("Hello")
f.write("World!")
## new_file.txt
HelloWorld!파일을 보면 띄어쓰기(' ')나 줄바꿈(\n)없이 문장이 붙어있음을 알 수 있다.
줄바꿈을 하려면 아래와 같이 작성하면 된다.
with open('new_file.txt, 'w') as f:
f.write("Hello\n")
f.write("World!\n")## new_file.txt
Hello
World!
그런데 이전에 작성한 내용이 삭제된 것을 확인할 수 있다. 이는 'w'는 전체를 지우고 새로 다시 쓰기 때문이다.
이를 방지하기 위해서는 'w'를 'a'로 바꾸어 사용하면 된다. a는 추가하다(append)의 약자이다.
with open('new_file.txt, 'a') as f:
f.write("Hello\n")
f.write("World!\n")## new_file.txt
Hello
World!
Hello
World!open('파일명', 'w')나 open('파일명', 'a')를 사용할 경우,
두 케이스 모두 기존에 없는 파일일 경우 새로 파일을 생성하여 내용을 삽입한다.
3. strip()
: 문자열 앞 뒤의 화이트 스페이스(white space, " ", "\t", "\n") 제거
위의 출력된 모습을 보면, 결과값이 한칸씩 띄워져 출력됨을 확인할 수 있다.
텍스트파일 자체에서 각 줄별 문자열에 (\n)이 있는 것으로 인식하고,
print문에서 end=''가 지정되지 않으면 기본적으로 줄바꿈이 되기 때문에 위와 같이 출력되는 것이다.
strip은 문자열 앞, 뒤의 화이트 스페이스(white space, " ", "\t", "\n")를 제거해주는 역할을 한다.
## 예시 (1)
print(" abc def ".strip())
>>> abc def
## 예시 (2)
print(" \t abc \n def \n ".strip())
>>> abc
>>> def이를 활용해 아래와 같이 코드를 수정하여 출력해보았다.
with open('test.txt', 'r', encoding='UTF8') as memo:
for line in memo:
print(line.strip())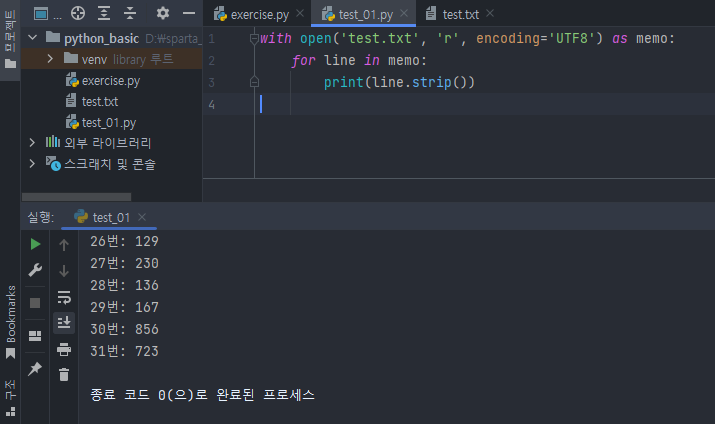
빈 줄이 없이 잘 출력되는 것을 확인할 수 있었다.
4. split()
: 문자열을 일정한 기준으로 쪼개고 싶을 경우 사용한다.
문자열.split("split 기준")아래와 같이 일정한 기준으로 쪼개어 리스트로 반환한다.
serial_num = "1. 2. 3. 4. 5. 6"
print(serial_num.split(". "))
>>> ['1', '2', '3', '4', '5', '6']리스트로 반환된 요소들은 아래와 같이 인덱싱으로도 사용할 수 있다.
name = "Kim, JongKook"
name_data = name.split(', ')
last_name = name_data[0]
first_name = name_data[1]
print(first_name, last_name)
>>> JongKook Kim화이트스페이스의 경우 split()의 괄호 안을 비워두면 깔끔하게 지울 수 있다.
print(" \n \n 2 \t 3 \n 5 7 6 \n\n ".split())
>>> ['2', '3', '5', '7', '6']주의할 점으로는 split으로 만들어진 리스트는 문자열(string)이므로
숫자로 사용하고 싶을 경우 int를 적용해주어야 한다.
num = " \n \n 2 \t 3 \n 5 7 6 \n\n ".split()
print(num[0] + num[1])
print(int(num[0]) + int(num[1]))
>>> 23
>>> 5
'DEV > 파이썬 이론' 카테고리의 다른 글
| 파이썬 코딩 :: 파이썬 모듈(Module) (0) | 2022.09.05 |
|---|---|
| 파이썬 코딩 :: 파이썬 문법, 알고리즘_TIL#05 (0) | 2022.09.02 |
| 파이썬 코딩 :: 파이썬 모듈(Module), 파이썬 스탠다드 라이브러리 (0) | 2022.09.02 |
| 파이썬 코딩 :: 파이썬 클래스(class) (0) | 2022.09.02 |
| 파이썬 코딩 :: 파이썬 map, filter, lambda (0) | 2022.09.02 |




댓글