
밑바닥부터 시작하는 딥러닝 Chapter 05. 오차역전파법(Backpropagation)
본 포스팅은
「밑바닥부터 시작하는 딥러닝 - 사이토 고키, 한빛미디어」라는 서적을 참고하였으며,
작성자가 공부한 내용을 기록하는 목적으로 작성하였습니다.
오차역전파법(Backpropagation)
신경망의 가중치 매개변수의 기울기를 구할 때, 수치미분은 단순하고 구현하기 쉽지만 계산시간이 오래 걸리는 단점이 있다. 이에 반해 오차역전파법은 효율적으로 가중치 매개변수의 기울기를 계산할 수 있다.
5.1 계산 그래프(Computational graph)
계산 과정을 그래프로 나타낸 것. 복수의 노트(node)와 에지(edge)로 표현된다.
5.1.1 계산 그래프로 풀다
계산그래프를 이용한 문제 풀이 흐름
1) 계산 그래프를 구성한다.
2) 그래프에서 계산을 왼쪽에서 오른쪽으로 진행한다.
ex) 계산그래프의 예시 - 하나에 100원인 사과 2개와 하나에 150원인 귤 3개를 소비세 10%에 사는 경우 지불 금액 계산하기

- 순전파(Forward propagation) : 계산을 왼쪽에서 오른쪽으로 진행
- 역전파(Back propagation) : 순전파의 역방향으로 계산을 진행
5.1.2 국소적 계산
국소적* 계산은 전체에서 어떤 일이 벌어지든 상관없이 자신과 관계된 정보만으로 결과를 출력하는 것을 말한다.
*국소적 : 자신과 직접 관계된 작은 범위

위 그림에서 4,000이라는 값이 사과의 갯수가 반영된 금액 200과 '+' 노드에서 계산될 경우, 4,000이라는 값이 이전에 어떤 계산을 거쳤는지 신경쓰지 않아도 된다는 것을 뜻한다.
5.1.3 왜 계산 그래프로 푸는가?
계산 그래프의 이점
1) 국소적 계산 : 단순한 계산에 집중하여 문제를 단순화 할 수 있다. 2) 중간 계산 결과를 모두 보관할 수 있다. 3) 역전파를 통해 '미분'을 효율적으로 계산할 수 있다.
5.2 연쇄법칙(Chain rule)
'국소적 미분'을 전달하는 원리는 '연쇄법칙'에 따른 것이며 이를 통해 계산그래프 상의 역전파를 설명할 수 있다.
5.2.1 계산 그래프의 역전파
y = f(x)라는 계산의 역전파를 계산그래프로 표현할 경우 아래와 같다.

역전파 계산 절차는 전달받은 신호 E에 노드의 국소적 미분 (dy/dx)을 곱한 후 다음 노드로 전달한다.
5.2.2 연쇄법칙이란?
아래와 같이 변수 x와 y로 이루어진 z라는 식이 있다고 할 때,
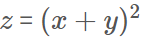
위 식은 아래처럼 두 개의 식으로 구성할 수 있으며 이때 z를 합성함수*라고 한다.
*합성함수 : 여러 함수로 구성된 함수
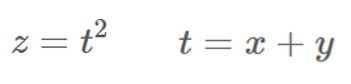
연쇄법칙은 합성함수의 미분에 대한 성질으로 아래의 성질을 나타낸다.
'합성함수의 미분은 합성함수를 구성하는 각 함수의 미분의 곱으로 나타낼 수 있다'

5.2.3 연쇄법칙과 계산 그래프
계산그래프의 역전파는 오른쪽에서 왼쪽으로 신호를 전달한다. 전달시 노드로 들어온 입력신호에 그 노드의 편미분을 곱한 후 다음 노드로 전달한다.

5.3 역전파
5.3.1 덧셈 노드의 역전파
덧셈 노드의 역전파는 입력 값에 1을 곱하기만 할 뿐이므로 그대로 다음 노드로 전달하는 성질이 있다.
ex) z = x + y 의 역전파

5.3.2 곱셈 노드의 역전파
곱셈 노드의 역전파는 오른쪽에서 왼쪽으로 신호를 전달하며 연쇄법칙에 의해 노드로 들어온 입력신호에 그 노드의 편미분을 곱한 후 다음 노드로 전달한다.
ex) z = x * y 의 역전파

5.3.3 사과 쇼핑의 예
'사과의 금액, 개수 소비세가 최종 금액에 어떤 영향을 주는가'라는 예시문제의 계산 그래프를 구하면 아래와 같다.
역전파로는 '사과 가격에 대한 지불 금액의 미분', '사과 개수에 대한 지불 금액의 미분', '소비세에 대한 지불 금액의 미분'이 해당된다.
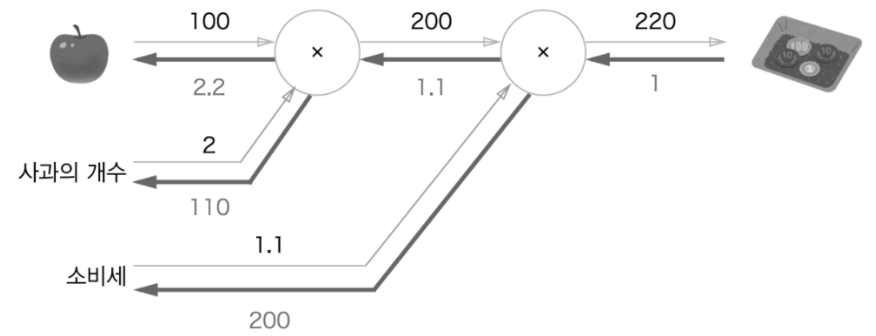
→ 위 그림에서는 소비세와 사과 가격이 같은 양만큼 오르면 최종 금액에는 소비세가 200의 크리고, 사과 가격이 2.2 크기로 영향을 준다고 해석할 수 있다. 단, 이 예에서 소비세와 사과 가격은 단위가 다르니 주의해야 한다.(소비세 1은 100%, 사과 가격 1은 1원)
5.4 단순한 계층 구현하기
5.4.1 곱셈 계층 (곱셈 노드, MulLayer)
class MulLayer:
def __init__(self):
self.x = None
self.y = None
def forward(self, x, y):
self.x = x
self.y = y
out = x * y
return out
def backward(self, dout):
dx = dout * self.y # x와 y를 바꾼다.
dy = dout * self.x
return dx, dy· __init__() : 인스턴스 변수인 x와 y를 초기화, 순전파 시의 입력값을 유지
· forward() : x와 y를 인수로 받고 두 값을 곱해서 반환
· backward() : 상류에서 넘어온 미분(dout)에 순전파 때의 값을 '서로 바꿔' 곱한 후 하류로 전달
이를 이용하여 5.3.3의 순전파와 역전파를 구현하면 아래와 같다.
# coding: utf-8
from layer_naive import *
apple = 100
apple_num = 2
tax = 1.1
# 계층들
mul_apple_layer = MulLayer()
mul_tax_layer = MulLayer()
# 순전파(forward propagation)
apple_price = mul_apple_layer.forward(apple, apple_num)
price = mul_tax_layer.forward(apple_price, tax)
# 역전파(backward propagation)
dprice = 1
dapple_price, dtax = mul_tax_layer.backward(dprice)
dapple, dapple_num = mul_apple_layer.backward(dapple_price)
# 출력값 확인
print("price:", int(price)) # price: 220
print("dApple:", dapple) # dApple: 2.2
print("dApple_num:", int(dapple_num)) # dApple_num: 110
print("dTax:", dtax) # dtax: 200
5.4.2 덧셈 계층
class AddLayer:
def __init__(self):
pass
def forward(self, x, y):
out = x + y
return out
def backward(self, dout):
dx = dout * 1
dy = dout * 1
return dx, dy· __init__() : 초기화가 필요없으므로 pass
· forward() : x와 y를 인수로 받고 두 값을 더해서 반환
· backward() : 상류에서 넘어온 미분(dout)을 그대로(1을 곱하여) 하류로 전달
예시) 사과 2개와 귤 3개 구입

# coding: utf-8
from layer_naive import *
apple = 100
apple_num = 2
orange = 150
orange_num = 3
tax = 1.1
# layer
mul_apple_layer = MulLayer()
mul_orange_layer = MulLayer()
add_apple_orange_layer = AddLayer()
mul_tax_layer = MulLayer()
# forward
apple_price = mul_apple_layer.forward(apple, apple_num) # (1)
orange_price = mul_orange_layer.forward(orange, orange_num) # (2)
all_price = add_apple_orange_layer.forward(apple_price, orange_price) # (3)
price = mul_tax_layer.forward(all_price, tax) # (4)
# backward
dprice = 1
dall_price, dtax = mul_tax_layer.backward(dprice) # (4)
dapple_price, dorange_price = add_apple_orange_layer.backward(dall_price) # (3)
dorange, dorange_num = mul_orange_layer.backward(dorange_price) # (2)
dapple, dapple_num = mul_apple_layer.backward(dapple_price) # (1)
print("price:", int(price))
print("dApple:", dapple)
print("dApple_num:", int(dapple_num))
print("dOrange:", dorange)
print("dOrange_num:", int(dorange_num))
print("dTax:", dtax)
5.5 활성화 함수 계층 구현하기
이제 계산 그래프를 신경망에 적용해본다. 여기에서는 신경망을 구성하는 층(계층) 각각을 클래스 하나로 구현한다.
5.5.1 ReLU 계층
활성화 함수 ReLU 그리고 ReLU함수의 미분은 아래와 같다.
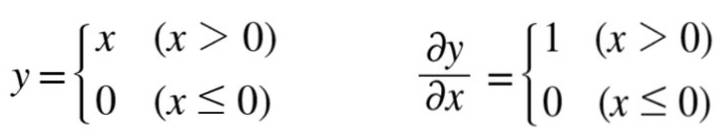
ReLU 계층은 x가 0보다 클 때, 작을 때를 구분하여 아래와 같이 계산 그래프를 그릴 수 있다. 즉, x가 0보다 클 때에는 상류의 값을 그대로 하류로 전달하지만, x가 0보다 작을 때에는 하류로 신호가 전달되지 않는다.(0이 전달된다)
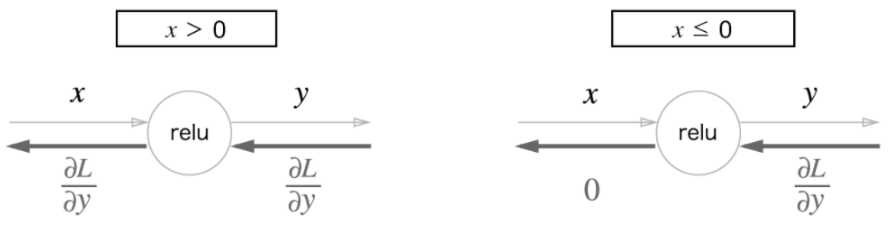
위의 속성을 통해 ReLU 계층은 파이썬으로 아래와 같이 구현할 수 있다.
class Relu:
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x <= 0)
out = x.copy()
out[self.mask] = 0
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx여기서 ReLU 클래스는 mask라는 인스턴스 변수를 가지는 것을 볼 수 있다. mask는 True/False로 구성된 넘파이 배열로, 순전파의 입력인 x의 원소값이 0 이하인 인덱스는 True, 그 외(0보다 큰 원소)는 False로 유지한다.
이러한 ReLU는 아래와 같이 전기회로에서 스위치에 비유하기도 한다.
- 순전파(Forward) : 전류가 흐르면 신호를 ON으로 하고 흐르지 않으면 OFF
- 역전파(Backward): 스위치가 ON이면 전류가 흐르고, OFF면 전류가 흐르지 않음
5.5.2 Sigmoid 계층
Sigmoid 함수와 이를 계산 그래프로 그리면 아래와 같다.
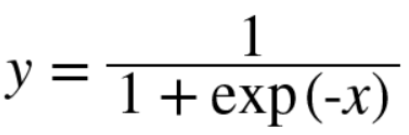

Sigmoid 함수에서는 ×와 +뿐 아니라 'exp'와 '/' 노드가 존재한다.
1단계) '/' 노드 : y = 1/x를 미분하고 y로 치환한 값을 곱하여 하류로 전달한다.
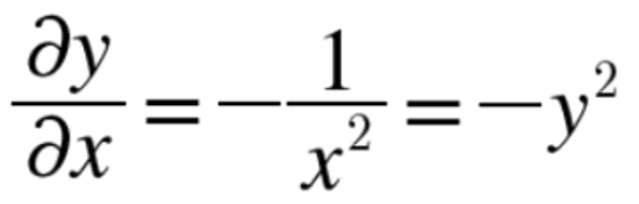
2단계) '+' 노드 : 상류의 값을 여과없이 하류로 전달한다.
3단계) 'exp' 노드 : y = exp(x) 연산을 수행하며 그 미분은 아래와 같다.

계산 그래프에서는 순전파 때의 출력 y = exp(-x)를 미분하고 이를 상류의 값과 곱하여 하류로 전달한다.
4단계) '×' 노드 : 순전파 때의 값을 서로 바꿔 곱한다. 이 예에서는 -1을 곱한다.
위의 1~4단계를 계산그래프로 표현하면 아래와 같으며, 우측과 같이 간소화 할 수 있다.

또한, 역전파의 결과값은 아래와 같이 정리하여 y에 대한 식으로 간소화 할 수 있다.

Sigmoid 계층은 아래와 같이 파이썬으로 구현할 수 있다.
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = sigmoid(x)
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx
5.6 Affine/Softmax 계층 구현하기
5.6.1 Affine 계층
신경망의 순전파 때 수행하는 행렬의 내적*은 기하학에서는 어파인 변환(Affine transformaiton)이라고 한다. 그렇기 때문에 어파인 변환을 수행하는 처리를 'Affine 계층'이라는 이름으로 정의한다. *행렬의 내적 : 행렬의 곱. 파이썬에서는 np.dot()으로 계산 (ex.뉴런의 가중치 합 : Y = np.dot(X, W) + B)

※ 주의 : 내적 계산시 행렬의 차원에 주의하여야 한다. (*대응하는 차원의 원소수를 일치화)
5.6.2 배치용 Affine 계층
데이터 N개를 묶어 순전파 하는 경우, 즉 배치용 Affine 계층을 표현하면 아래와 같다.
기존과 다른 부분은 입력인 X의 형상이 (N, 2)가 된 것 뿐이고, 그 뒤로는 계산 그래프의 순서에 따라 행렬계산을 한다.

편향을 더할 때는 주의해야 한다. 순전파의 편향 덧샘은 X·W에 대한 편향이 각 데이터에 더해진다. 그래서 역전파 때는 각 데이터의 역전파 값이 편향의 원소에 모여야 하고 그 코드는 아래와 같다.
dY = np.array([ [1, 2, 3], [4, 5, 6] ])
dB = np.sum(dY, axis = 0) # axis = 0 : 0번째 축에 대한 총 합
print(dB)
>>> array([5, 7, 9])
Affine을 파이썬으로 구현하면 아래와 같다.
class Affine:
def __init__(self, W, b):
self.W = W
self.b = b
self.x = None
self.original_x_shape = None
# 가중치와 편향 매개변수의 미분
self.dW = None
self.db = None
def forward(self, x):
# 텐서 대응
self.original_x_shape = x.shape
x = x.reshape(x.shape[0], -1)
self.x = x
out = np.dot(self.x, self.W) + self.b
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
dx = dx.reshape(*self.original_x_shape) # 입력 데이터 모양 변경(텐서 대응)
return dx
5.6.3 Softmax-with-Loss 계층
소프트맥스 함수는 아래와 같이 입력값을 정규화(출력의 합이 1이 되도록 변환)하여 확률값을 출력한다.

신경망에서 수행하는 작업은 학습과 추론 두 가지이며, 이 작업에 따라 Softmax를 사용할지 결정된다.
- 추론할 때에는 일반적으로 Softmax 계층을 사용하지 않는다. 예를 들어 위의 그림의 신경망을 추론할 때는 마지막 Affine 계층의 출력을 인식 결과로 이용한다.
- 또한, 신경망에서 정규화하지 않는 출력결과(위 그림의 Affine계층의 출력)를 점수(Score)라 한다.
→ 즉 신경망 추론에서 답을 하나만 내는 경우에는 가장 높은 점수만 알면 되기 때문에 Softmax 계층은 필요하지 않다는 의미이며, 신경망을 학습할 때에만 Softmax 계층을 사용한다.
소프트 맥스 계층을 구현할 때 손실 함수인 교차 엔트로피 오차도 포함하여 Softmax-with-Loss 계층이라는 이름으로 구현되며 아래와 같이 계산 그래프를 그릴 수 있다.

이 계산 그래프는 아래와 같이 간소화하여 표현 가능하다.
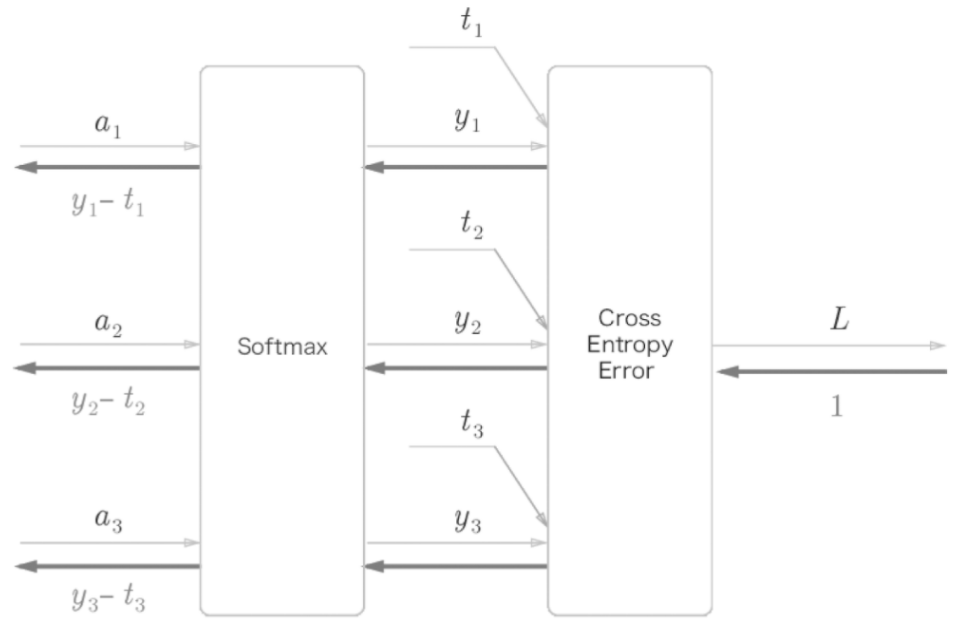
여기서 주목할 점은 Softmax 계층의 역전파는 (y_1 - t_1, y_2 - t_2, y_3 - t_3)과 같이 (Softmax의 출력 - 정답레이블) 쌍으로 차분값을 결과로 내놓고 있는 점이다. 즉, 신경망의 현재 출력과 정답 레이블의 오차를 그대로 드러내고 있다. 이는 교차 엔트로피 오차의 속성 때문에 나타나는 결과이다.
*회귀의 출력증에서 사용하는 '항등 함수'의 손실함수로 '평균 제곱 오차'를 이용할 때에도 역전파의 결과가 (y_1 - t_1, y_2 - t_2, y_3 - t_3)으로 말끔히 떨어진다.
Softmax-with-Loss 계층을 파이썬으로 구현한 코드는 아래와 같다.
class SoftmaxWithLoss:
def __init__(self):
self.loss = None # 손실함수
self.y = None # softmax의 출력
self.t = None # 정답 레이블(원-핫 인코딩 형태)
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
if self.t.size == self.y.size: # 정답 레이블이 원-핫 인코딩 형태일 때
dx = (self.y - self.t) / batch_size
else:
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size
return dx
5.7 오차역전파법 구현하기
5.7.1 신경망 학습의 전체 그림
앞서 4.5에서 다루었던 '신경망 학습의 절차'는 아래와 같으며, 오차역전파법은 두 번째 '기울기 산출'에서 적용된다.
- 1단계(미니배치) : 훈련 데이터 중 일부를 무작위로 가져와서 데이터를 선별한다.(미니배치 생성)
- 2단계(기울기 산출) : 미니배치의 손실 함수 값을 줄이기 위해 가중치 매개변수의 기울기를 구한다.
- 3단계(매개변수 갱신 및 1~3단계 반복) : 가중치 매개변수를 기울기 방향으로 조금씩 갱신하며 반복한다.
수치 미분과 비교했을 때, 수치 미분은 구현이 쉽지만 느리고, 오차역전파법은 기울기를 효율적이고 빠르게 구할 수 있다.
5.7.2 오차역전파법을 적용한 신경망 구현하기
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
import numpy as np
from common.layers import *
from common.gradient import numerical_gradient
from collections import OrderedDict
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std = 0.01):
# 가중치 초기화
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
# 계층 생성
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.lastLayer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
# x : 입력 데이터, t : 정답 레이블
def loss(self, x, t):
y = self.predict(x)
return self.lastLayer.forward(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# x : 입력 데이터, t : 정답 레이블
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 결과 저장
grads = {}
grads['W1'], grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W2'], grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads


- 여기서 신경망의 계층을 OrderedDict에 저장함으로써 딕셔너리에 추가한 순서대로 각 계층의 forward() 메서드를 호출하고, backward() 메서드에서는 반대 순서로 호출한다.
- 이처럼 신경망의 구성요소를 '계층'으로 모듈화하여 구현하면 추후 깊은 신경망을 만들 때에도 단순히 필요한 만큼 계층을 추가하면 되기 때문에 간편해지는 효과가 있다.
5.7.3 오차역전파법으로 구한 기울기 검증하기
앞서 수치미분은 느린 단점이 존재했지만 구현하기 쉽다는 장점이 있기 때문에 버그를 찾기 쉽고, 오차역전파법을 검증하는 데 사용될 수 있다. 이렇게 두 방식의 기울기의 일치를 확인하는 것이 기울기 확인(gradient check)이라고 하며 아래와 같이 구현할 수 있다.
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
# 데이터 읽기
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
x_batch = x_train[:3]
t_batch = t_train[:3]
grad_numerical = network.numerical_gradient(x_batch, t_batch)
grad_backprop = network.gradient(x_batch, t_batch)
# 각 가중치의 절대 오차의 평균을 구한다.
for key in grad_numerical.keys():
diff = np.average( np.abs(grad_backprop[key] - grad_numerical[key]) )
print(key + ":" + str(diff))
5.7.4 오차역전파법을 사용한 학습 구현하기
# coding: utf-8
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
# 데이터 읽기
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 기울기 계산
#grad = network.numerical_gradient(x_batch, t_batch) # 수치 미분 방식
grad = network.gradient(x_batch, t_batch) # 오차역전파법 방식(훨씬 빠르다)
# 갱신
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(train_acc, test_acc)
'DataScience > 딥러닝' 카테고리의 다른 글
| 파이토치(PyTorch) 딥러닝 모델링 전략 (2) - 파이토치 딥러닝 모델링 단계 (0) | 2024.06.30 |
|---|---|
| 파이토치(PyTorch) 딥러닝 모델링 전략 (1) - 모델링 할 때 지녀야 할 마인드셋 (0) | 2024.06.30 |
| 딥러닝 :: 밑바닥부터 시작하는 딥러닝 Chap4. 신경망 학습 (0) | 2023.05.05 |
| 딥러닝 :: 밑바닥부터 시작하는 딥러닝 Chap3. 신경망 (0) | 2023.05.03 |
| 딥러닝 :: 밑바닥부터 시작하는 딥러닝 Chap2. 퍼셉트론 (0) | 2023.05.02 |




댓글