
강화학습_DRL, MDP(Markov Decision Process)
1. 개요
※ 머신러닝의 종류(3가지)
1) Supervised Learning (지도학습)
: 레이블이 있는 데이터로부터 훈련하여 학습한다.
: 주로 회귀(Regression), 분류(Classification) 방식으로 학습
2) Unsupervised Learning (비지도학습)
: 레이블 없는 데이터를 통해 학습한다.
: 상대적으로 지도학습보다 다수의 데이터가 필요
: 주로 데이터내 유사한 성격을 가진 데이터를 찾아내는 군집(Cluster) 방식으로 패턴을 찾는다.
3) Reinforcement Learning (강화학습)
: 샘플 데이터 없이 환경에 따른 상호작용을 통해 학습한다.
: Agent가 각 상황(State)에 따른 행동(Action)을 하며 행동에 따른 보상(Reward)을 받아 학습한다.
: 학습을 진행할 수록 총 보상(Total reward)이 최대가 되게 하는 방향으로
각 상태에 따른 행동방식(Policy)을 업데이트하며 학습한다.

※ 머신러닝과 딥러닝의 차이?
1) 일단 머신러닝은 사람이 직접 패턴(또는 Feature)을 추출하는 작업이 필요하다. 이러한 작업을 Feature Engineering이라 하는데 이는 시간도 많이 소요되며, 상황에 따라 불완전하고 어려운 작업이다.
2) 딥러닝은 머신러닝에서 사람이 수행하는 Feature Engineering에 대한 부분을 수많은 Layer를 쌓은 구조의 Deep Neural Network를 이용하여 자동으로 수행하는 end-to-end learning으로, 역전파를 통해 gradient를 계산해가며 수많은 parameter를 계산해낸다. 이를 통해 도메인 지식에 대한 의존성은 매우 줄었지만, 수많은 양의 input raw data를 필요로 하며, layer가 많은 만큼 계산해야 하는 parameter가 매우 많다.
※ Deep Reinforcement Learning이란?
딥러닝(Deep Learning)과 강화학습(Reinforcement Learning)의 혼합된 단어로, 강화학습에 딥러닝의 장점을 활용한 학습방식을 말한다. DQN(DeepMind 2013)과 AlphaGo(Google DeepMind 2016)이 그 예이다.
2. Markov Decision Process
1) Grid World Example
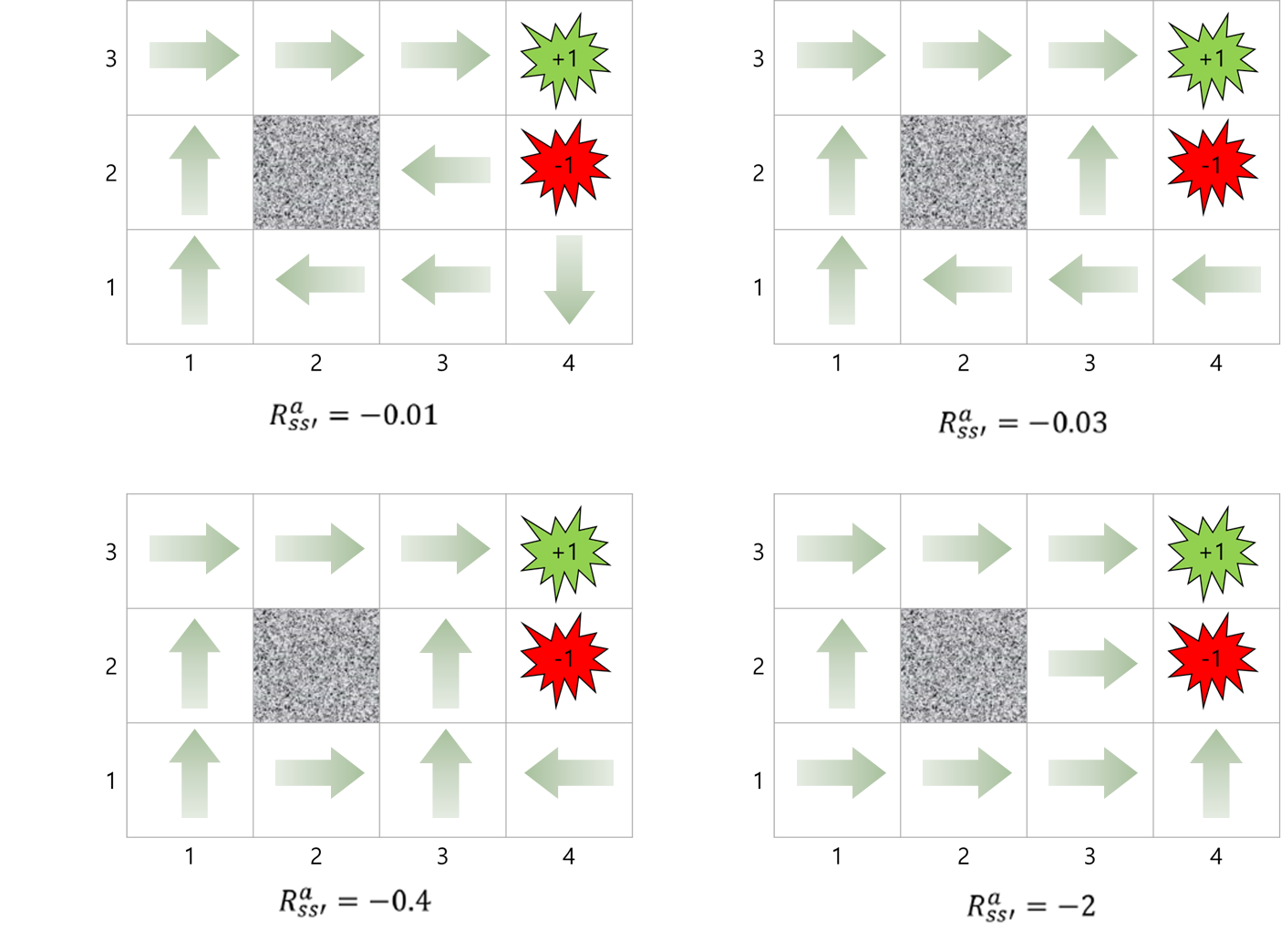
- 아래 그림과 같이 Agent가 각 State(Grid의 위치)에서 이동(동, 서, 남, 북)하는 경우를 예시로 하여 강화학습을 이해할 수 있다. 아래 그림에서 State, Action, Reward는 아래와 같으며, total reawrd를 최대로 하는 각 state에 대한 Action을 선택하는 것(Optimal Policy)을 목표로 한다.
· State = {(1, 1), (1, 2), ..., (4,3)} but (2, 2)는 벽으로 제외
· Action = {동, 서, 남, 북}
· Reward
① Big reward : (4,3)일 경우 +1점, (4, 2)일경우 -1점
② Small (negative) reward : 1회의 Action을 수행할 때 마다 c만큼의 reward 적용
- 이 때, Agent는 noisy movement를 가정하며, State transition probability에 따라 움직인다.
이는 Stochastic grid world(↔Deterministic grid world)를 가정하며, 같은 Action/State에도 무작위성에 따라 출력(output)이 변화한다.
(ex. Action이 북쪽으로 수행된다면, Agent는 80%확률로 북쪽으로 이동하고, 10%는 서쪽, 10%는 동쪽으로 이동한다)

2) Markov Property
- Markov Property는 오직 직전 상태에 따라 다음상태를 결정하는 특징(직전 이전 과거의 상태에 영향을 받지 않음)을 뜻하며, 이러한 특징을 갖는 것을 Markov Process(또는 Markov chain)라고 한다. (*Brownian motion과 유사) Markov Process는 tuple (S, P)로 나타낼 수 있으며, 이 때, S는 state의 집합, P는 state transition probability matrix [Pij]이다.
- 이러한 Markov Process에 대한 확률은 아래의 수식과 같이 표현할 수 있으며, 이는 상태 s로부터 s'에 대한 State transition probability이라고 부른다.
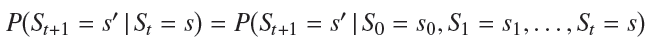
3) Markov Decision Process (MDP)
- MDP는 앞서 소개했던 Markov Process에서 확장한 개념을 뜻하며, 모든 상태가 Markov Property를 따를 경우에 State, Reward를 추가하여 tuple(S, A, P, R, γ)로 나타낼 수 있다.
(S : state space, A : action space, P : (state) transition probability, R : reward function, γ∈[0, 1] : discount factor)

- 이 때 MDP에 대한 정보(transition probability, 각 State에 대한 Action, Reward)를 미리 알고 있는 것을 Model-based, 그렇지 않은 것을 Model-free라고 한다. Model-based와 같이 State와 Action, 그리고 Probability에 대한 방대한 정보를 통해 학습하는 것을 Dynamic Programming이라고 한다.
4) Optimal Policy
- MDP에서는 total reward를 최대로 하는 Optimal policy(π*)를 찾아내는 것이 목적이다.
- 아래 그림과 같이 small reward의 크기에 따라 각 State에 대한 Action이 달라지게 된다.
- 첫번째 그림은 small reward가 매우 작아서 최대한 안전한 방향으로 Agent를 이동시키지만, 4번째 그림은 small reward가 매우 커서 이동시키는 것 보다 실패(-1)하더라도 빠르게 종료시키는 것이 더 합리적이라고 판단한다. 따라서 가장 합리적인 방법은 세번째 그림이라고 판단된다.
댓글